malloc Is Not Free
You Called malloc(64). Here's What Actually Happened.
Reading time: ~13 minutes
You called malloc(64). You got a pointer back. You stored your data. You moved on.
The kernel, the MMU hardware, the page table walker, and possibly the disk were all involved.
Not necessarily in every malloc call — your allocator is pretty clever about batching all that work. But at some point, behind that innocent function call, something had to go talk to the operating system, the OS had to talk to the memory hardware, and the hardware had to talk to RAM. Understanding where that happens — and when — is the difference between "I wonder why this crashed" and "oh, of course it crashed."
The Bug That Changed How We Allocate
Picture this: a service allocates a 512MB buffer at startup, does a quick sanity check, then proceeds with the real work. It runs fine in staging. In production, under load, it OOM-kills itself hours later.
The buffer was allocated. No error. The pointer was valid. The problem was that allocating memory and having memory are two different things in Linux — and we'll explain exactly why in the next three sections.
If you've ever seen a SIGSEGV on a line that seemed obviously fine, or watched a program get killed by the OOM killer when it had "plenty of memory," or wondered why valgrind sometimes finds bugs that asan misses — this is the layer where that happens.
The First Player: Your Allocator
When you call malloc(64), the first thing that intercepts your request is not the kernel. It's a userspace library — ptmalloc2 if you're on glibc (the default on most Linux systems), or jemalloc if you're on Firefox or FreeBSD, or Daan Leijen's mimalloc (2019, Microsoft Research) if you're on something that prizes both speed and memory efficiency.
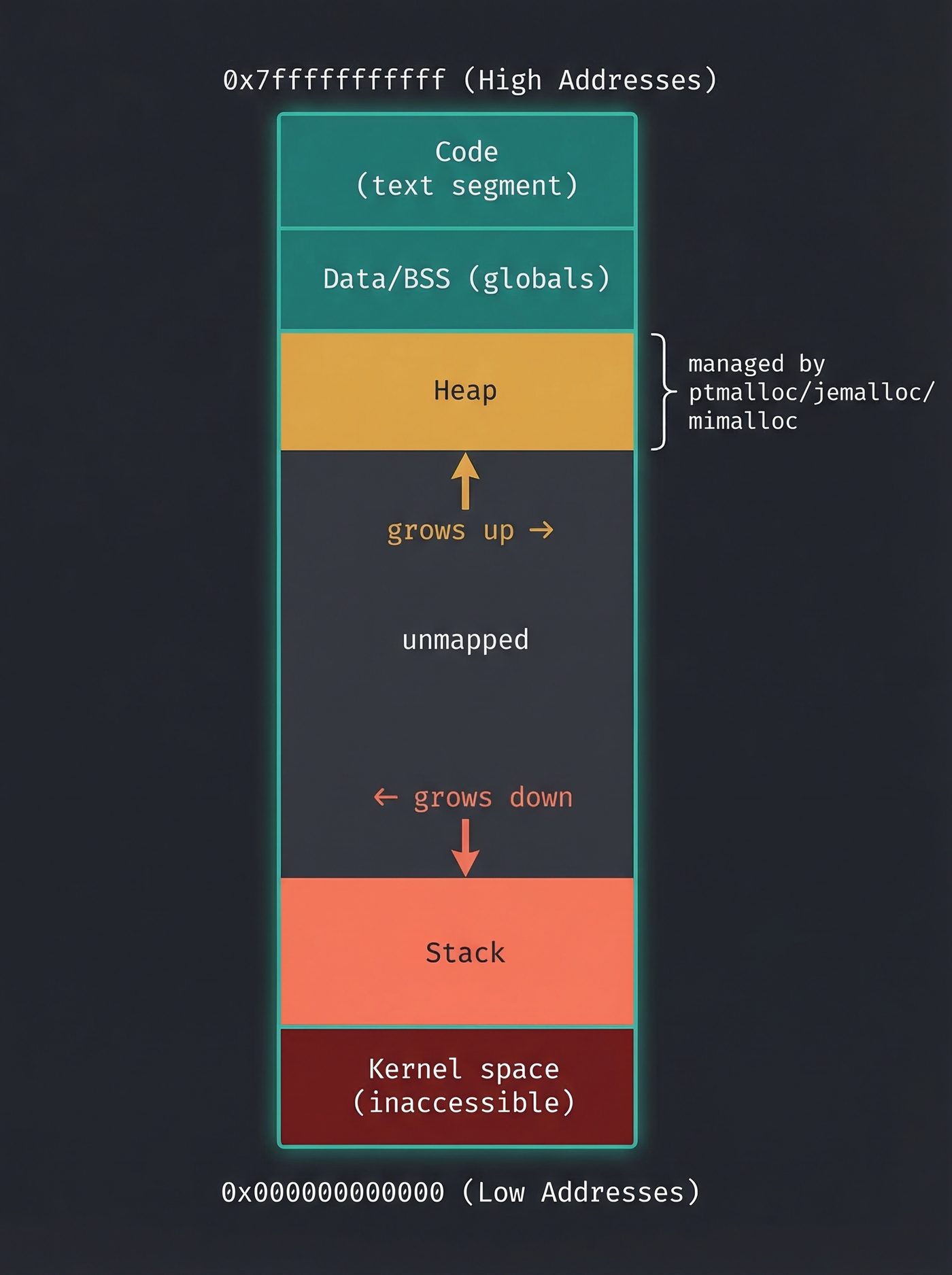
The allocator's job is to be fast by being greedy. On its first run, it asks the kernel for a big chunk of memory — far more than your 64 bytes. Then it subdivides that chunk itself, handing out pieces to your program without involving the kernel at all.
This pool of memory is called the heap. It's not a fixed-size thing. It starts small and grows on demand. The allocator manages it with data structures (linked lists of free blocks, size-class bins, various clever tricks depending on which allocator you're using) and tries hard to satisfy your requests from memory it already has.
Most malloc calls never reach the kernel. That's the whole point.
That's why Java, Python, and Rust programs appear to use far more RAM than you'd expect. Their allocators (and the JVM/runtime heap managers) request large chunks upfront from the kernel to amortize the syscall overhead. The virtual size looks enormous. The resident size — physical pages actually in RAM — is often much smaller.
When the Pool Runs Dry
But eventually, the allocator's pool fills up. You've handed out more than you initially reserved. Time to ask the kernel for more.
The allocator has two ways to do this:
brk() / sbrk() — the old way, and still used for small allocations. These syscalls move the "program break" — a pointer that marks the end of the heap segment. Move it up, and the virtual address space between the old break and the new break is yours.
mmap() — the modern way, used for large allocations (typically over 128KB, though the threshold is configurable). mmap() asks the kernel for a new anonymous mapping — a fresh region of virtual address space not backed by any file. (You saw mmap doing file-backed work in What Actually Happens When You Read a File — here it's the same syscall, but for memory that doesn't map to a file at all.)
Both syscalls return to the allocator with a pointer to a new region of virtual address space. The allocator updates its internal bookkeeping, carves off the chunk you asked for, and returns it to you.
Here's the thing: this all happens extremely fast. The kernel updates a data structure and returns. No RAM has been touched. No physical memory has been allocated. The pointer you receive points to... nothing, yet.
The Kernel's Comfortable Lie
This is the part that bends everyone's brain the first time: virtual memory is a lie the kernel tells your program.
Your process has a virtual address space — on a 64-bit system, a staggering 128TB of addressable space, minimum. The kernel hands you slices of this virtual space freely. It's cheap. It's just numbers in a data structure.
Physical RAM is different. Physical RAM is scarce. A machine with 16GB of RAM has 16GB of RAM, and sharing it across dozens of processes requires actual bookkeeping.
The kernel resolves this tension with a policy called overcommit. When your allocator calls mmap() for 512MB, the kernel doesn't check whether 512MB of physical RAM is available. It checks whether 512MB of virtual address space is available (almost always yes), updates its virtual memory map, and returns success.
The assumption is: you'll never actually touch all that memory. Most programs allocate a lot and use a fraction. The kernel is gambling on this, and statistically it wins.
This is why you can malloc(500GB) on a machine with 8GB of RAM, get a non-NULL pointer back, and not crash — until you actually try to use it.
That's why malloc returning non-NULL doesn't mean you have memory. The kernel said yes to the virtual address. It hasn't committed any RAM. You find out at first write, via a page fault — or, if RAM is truly exhausted, via the OOM killer.
// This does NOT allocate 1GB of physical RAM. It reserves
// 1GB of virtual address space. Pages only become real on first write.
char *p = malloc(1024 * 1024 * 1024);
assert(p != NULL); // passes on most Linux systems with default overcommit settings
p[0] = 1; // *this* is when things get interesting
The Page Fault: Where Memory Gets Real
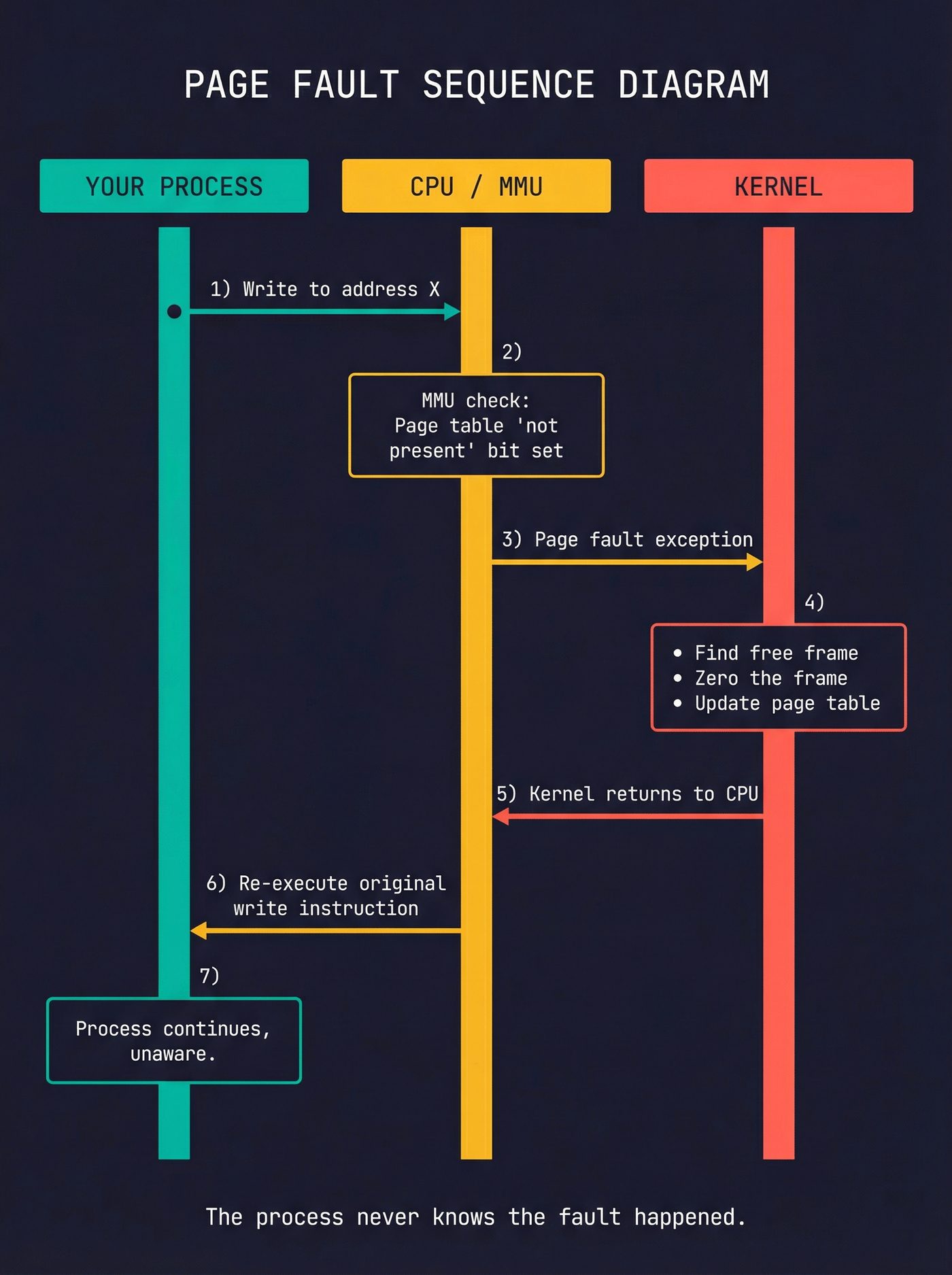
You write to your newly allocated memory for the first time. The CPU translates the virtual address to a physical address using the page table — a tree of mappings the kernel maintains for each process.
The page table entry for your address says: "valid virtual address, but no physical frame assigned yet."
The CPU raises a page fault. This is a hardware exception — the CPU stops executing your instruction, saves its state, and jumps to the kernel's page fault handler. Your process is suspended, mid-instruction, while the kernel handles it.
The page fault handler looks at the virtual address and decides what to do. For a freshly allocated anonymous page, the answer is:
- Find a free physical frame (a 4KB chunk of RAM)
- Zero it out — this is a security requirement enforced by the kernel. Without it, you'd get physical memory that still contains another process's data. POSIX mandates zeroing for
mmapwithMAP_ANONYMOUS, but Linux zeroes all new pages regardless, because handing out stale memory is how you get information leaks. - Write the mapping into the page table: "this virtual address → this physical frame"
- Flush the relevant address translation cache entry (the TLB — more on this in a moment)
- Return to the CPU, which re-executes the faulting instruction
Your process resumes, completely unaware that anything happened. From your code's perspective, you just wrote to a pointer. But you actually just caused a hardware exception, ran kernel code, and allocated physical RAM.
This is demand paging — the kernel is lazy by design. It doesn't allocate physical memory until you demand it by accessing the page.
The Page Table: A Tree the Hardware Walks
Every memory access your process makes — every load, every store, every function call — has to go through address translation. The CPU takes your virtual address and turns it into a physical address.
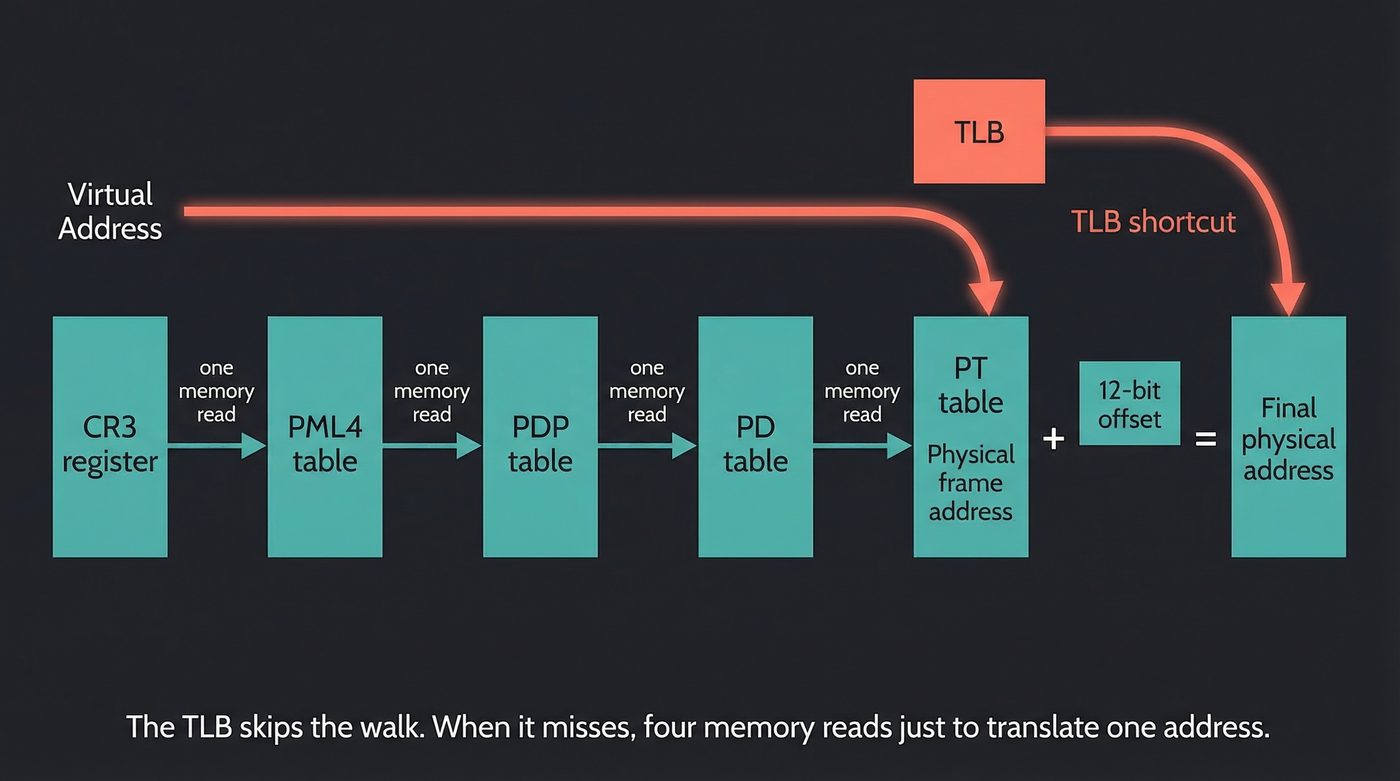
This translation happens in hardware, in a component called the MMU (Memory Management Unit). The MMU walks the page table — a multi-level tree structure that the kernel maintains in RAM.
On x86-64 with the common 4-level configuration, a 64-bit virtual address is split into five fields:
63 48 47 39 38 30 29 21 20 12 11 0
┌───────────┬───────┬───────┬───────┬───────┬──────────┐
│ (unused) │ PML4 │ PDP │ PD │ PT │ Offset │
└───────────┴───────┴───────┴───────┴───────┴──────────┘
16 9 9 9 9 12
Each level is a 512-entry table stored in a physical page. The MMU starts at the PML4 (the root, whose physical address is stored in x86-64's CR3 register — ARM64 calls the equivalent TTBR0_EL1, but the concept is identical), indexes into it with bits 47–39, follows the pointer to the next level, indexes again, and so on down until it has the physical address of the page. It then adds the 12-bit offset to get the final physical byte address. Every architecture with virtual memory does some version of this walk — the number of levels and register names change, but the tree structure is universal.
That's four memory reads just to translate one address. On every. Single. Memory. Access.
Obviously, this would be catastrophically slow if it really happened that way. The hardware maintains a cache for recent translations: the TLB (Translation Lookaside Buffer). Most address translations hit the TLB and cost a single cycle or two. When the kernel updates a page table entry — as it does during a page fault — it has to flush the affected TLB entries, or the CPU would use stale translations.
TLB flushes are one reason context switches are expensive. When the kernel switches from your process to another, it loads the other process's page table root into CR3, which invalidates (most of) the TLB. The next process has to re-warm the TLB from scratch.
Spectre and Meltdown exploited the relationship between virtual memory and CPU caches to leak data across process boundaries. The attacks used speculative execution to access memory the process shouldn't see, then measured cache timing — not TLB timing — to observe what was read. The cache side-channel is the key: a speculatively loaded cache line leaves a timing fingerprint even after the speculative execution is rolled back. I cover the full mechanism in How Your Python Code Actually Runs.
When There Are No Free Frames
The page fault handler needs a free physical frame. What if there aren't any?
This is where the kernel earns its keep.
Reclaim path. The kernel's memory management subsystem maintains lists of physical frames sorted roughly by how recently they were accessed — this is the LRU (Least Recently Used) approximation. When free frames run out, the kernel tries to reclaim some.
Clean pages — pages whose content matches what's on disk (think: file-backed mmaps, shared libraries) — can be simply discarded. The data is already on disk. If the process touches that page again, it page-faults back in. No data lost, just latency.
Dirty pages — pages with data that exists only in RAM — have to be written somewhere before the frame can be reused. If swap space is configured, they go to swap. The page table entry is updated to "swapped out, here's the location on disk." If the process touches that page again, it takes a much more expensive page fault (disk I/O), the page is read back from swap, and execution resumes.
That's why mlock() exists. If you need to guarantee that a page stays in RAM — real-time audio processing, cryptographic keys that must never touch swap — you call mlock(). This forces the page fault to happen immediately and pins the physical frame.
When even that isn't enough. If the kernel has churned through its reclaim options and still can't find a free frame, it invokes the OOM killer: the out-of-memory killer. This is a last-resort mechanism that selects a process — based on a scoring heuristic that considers memory usage, process priority, how long it's been running, and a few other factors — and kills it with SIGKILL.
The process has no say. There's no handler to catch it. One frame you're executing instructions. Next frame, black. No cut scene. No credits. As Henry Hill would say — "And that's that."
If you've ever had a long-running service vanish with no error, no log entry, no exit code — check /var/log/kern.log or dmesg for "Out of memory: Kill process". There's a very good chance the OOM killer found you before you found it.
Fork and the Copy-On-Write Trick
Demand paging enables one of the most useful cheap operations in Unix: fork().
fork() duplicates the parent's entire virtual address space, but it doesn't copy any of the physical pages. Instead, it marks all pages copy-on-write (COW): both parent and child map to the same physical frames, but the page table entries are marked read-only. The first write to any page by either party triggers a page fault; the handler copies that one frame, and the two processes get independent copies.
A thousand-page process can fork in microseconds.
That's why web servers and shell pipelines can spawn child processes so cheaply — the kernel is not copying megabytes of RAM, it's updating page table entries.
The Stack Is Different
One more thing worth knowing: the stack is handled differently from the heap.
The stack starts at a fixed virtual address and grows downward (on x86). The kernel doesn't actually map all of it upfront — it only maps a few pages, and relies on page faults to extend it when needed. If your function goes deeper, it faults into a new page, the kernel checks that it's still within the stack's allowed region, and extends the mapping.
This is also why stack overflows aren't caught by malloc failure — you don't call any allocator function. You just write past the end of the stack's mapped region, hit a page that was deliberately left unmapped (the guard page), and get a segfault. The guard page is not an accident; it's there specifically to catch stack overflows.
void infinite_recurse(int n) {
char buffer[4096]; // touches a new stack page on each call
buffer[0] = n; // force the page to be mapped
infinite_recurse(n + 1);
// → SIGSEGV on guard page after ~8000-16000 frames (default 8MB stack)
}
What You Actually Control
The system we've described is mostly automatic. But you have more control than you might think:
/proc/sys/vm/overcommit_memory— set to2to disable overcommit entirely.mallocwill return NULL when memory is actually exhausted. This is appropriate for databases and other programs that prefer a clean error to a sudden kill.mlock()/mlockall()— pin pages in RAM, prevent swapping.madvise()— tell the kernel how you plan to use a memory region.MADV_SEQUENTIALlets it read-ahead pages.MADV_FREEtells it the pages are unused and can be reclaimed.malloc_trim()(glibc-specific) — tell the allocator to release unused heap memory back to the kernel. Useful for long-running services that allocate a lot and then don't.LD_PRELOADswap — because allocators are userspace, you can swap them out entirely. Replace ptmalloc with jemalloc or mimalloc by settingLD_PRELOAD. Companies have done this to get 10–30% memory savings and significant throughput improvements with zero code changes.
The Full Picture
Let's run malloc(64) one more time, end to end:
- Your code calls
malloc(64). - The allocator checks its free list. If a suitable chunk exists, it returns a pointer immediately. Done.
- If not, the allocator calls
mmap()(orbrk()) to request more virtual address space from the kernel. - The kernel updates the virtual memory area (VMA) list for your process. No physical RAM involved yet.
- The allocator carves off 64 bytes and returns the pointer.
- Your code writes to that pointer for the first time.
- The MMU translates the virtual address. Page table says: valid range, no physical frame.
- CPU raises a page fault.
- Kernel page fault handler runs. Finds a free physical frame. Zeroes it. Updates page table. Flushes TLB entry.
- CPU re-executes the faulting instruction. The write completes.
- Your program continues, completely unaware that hardware exceptions and kernel code were involved.
That's the machinery behind a function call so common you type it without thinking.
Further Reading
man 2 mmap,man 2 brk— The kernel interfaces your allocator actually uses.man 2 mlock— How to pin memory in RAM if you need a guarantee.- Understanding the Linux Virtual Memory Manager — Mel Gorman's book, available free online. The definitive deep dive into everything above and more.
/proc/<pid>/mapsand/proc/<pid>/smaps— Watch your own process's virtual memory regions in real time.smapsshows RSS (resident set size) per region — the difference between virtual and physical becomes very concrete very fast.- What every programmer should know about memory — Ulrich Drepper's 2007 paper. Still the best single document on the full memory hierarchy.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri once had the OOM killer murder his database at 3am and deserved it. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.