The Paper That Made Distributed Systems Possible
Byzantine Generals, Traitorous Nodes, and the Math of Trust
Reading time: ~16 minutes
It's 1982. Leslie Lamport, Robert Shostak, and Marshall Pease publish a paper in the ACM Transactions on Programming Languages and Systems about Byzantine army generals trying to coordinate an attack on a city. Each general can send a messenger to every other general and the messages do arrive — the problem isn't a flaky network, it's that some of the generals might be traitors who send contradictory orders to different allies. The question the paper asks: how many loyal generals do you need to guarantee that the loyal ones all agree on the same plan?
This sounds like something from a game theory textbook, or maybe a dinner party puzzle for mathematicians who've had too much wine. It is the single most important problem formulation in distributed computing. Every replicated database, every blockchain, every multi-region service you've ever deployed sits on top of the answer to this question.
And Lamport chose Byzantine generals specifically. Not because he was a history buff (though he is). Because the analogy was perfect.
A Quick History Lesson
Most readers will see "Byzantine" and either not know what it means or think it's a synonym for "weird and overcomplicated." The word does mean both of those things in modern English, and that secondary meaning is exactly because of the actual Byzantine Empire — but the empire came first.
By the late third century, the Roman Empire had grown so vast that ruling it from a single capital was impossible. The Mediterranean was a Roman lake, but message travel times across that lake were measured in weeks. So in 285 AD, Emperor Diocletian split administration between a Western half (with the court at Mediolanum — modern Milan — not Rome) and an Eastern half (with the court at Nicomedia — modern Izmit, Turkey). Two emperors, two courts, one notional empire. Constantinople — modern Istanbul — didn't exist yet. Constantine the Great would found it as the new eastern capital in 330 AD, forty-five years later, on the site of an old Greek colony called Byzantion. Aha!
In 476 AD, the Western Roman Empire collapsed. Barbarian generals, economic decay, the usual. This is the date schoolchildren learn as "the fall of Rome."
The Eastern half didn't fall. It kept going. For another thousand years. From 476 until 1453, when the Ottoman Turks finally took Constantinople, the Eastern Roman Empire was a continuous, functioning state. They still called themselves Romans. They still spoke Greek (which had been the empire's eastern lingua franca since Alexander). They preserved Roman law, Roman administration, Roman engineering — and they fought constant wars to hold their borders against Persians, Arabs, Slavs, Bulgars, Crusaders, and eventually Ottomans.
Western European historians, writing centuries later, called them "Byzantines" after the old Greek city of Byzantion that Constantinople had been built on. The name stuck. And because the Byzantine court was famous for its labyrinthine ceremonial protocols, factional intrigue, and cloak-and-dagger politics — emperors blinded by rivals, generals plotting against one another, succession contests resolved by murder — the word "byzantine" entered English as a synonym for any system that's tortuous, scheming, and full of hidden agendas.
That's the world Lamport reached for. Not weird-because-foreign. Weird-because-the-people-on-your-own-side-might-be-actively-deceiving-you. The Byzantine court's reputation for treachery is exactly the failure mode his paper needed to model: not crashed nodes, not lost messages, but malicious actors who look loyal.
The Siege
Picture it concretely.
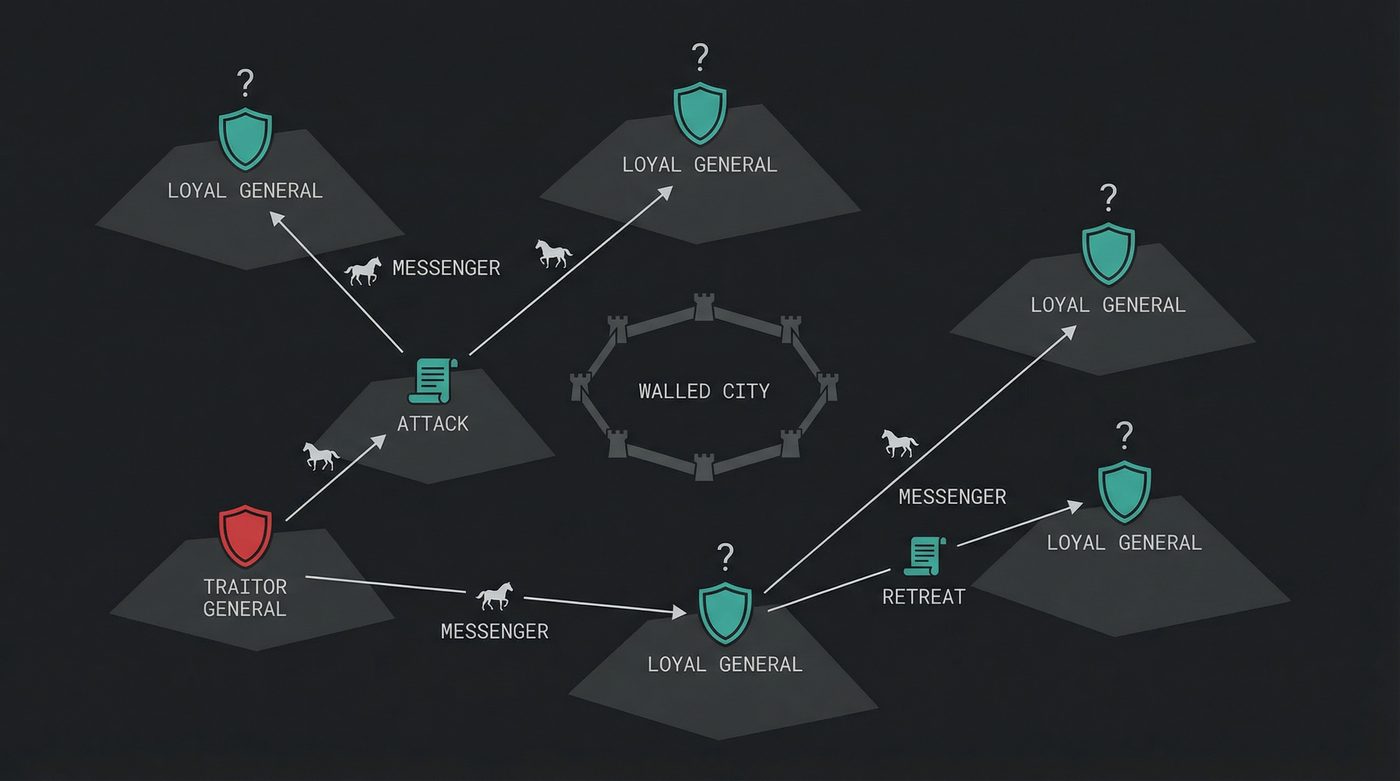
Five generals of the Byzantine army have surrounded an enemy city. They're camped on different hills. They can't see each other. Their only communication is messengers on horseback riding between the camps. They need to decide: do we attack at dawn, or do we retreat?
The rules are cruel. If all five attack, they win. If all five retreat, they survive to fight another day. But if three attack and two retreat, the three attackers get slaughtered. Split action is catastrophe. They must agree.
Here's the problem: General Theodora might be a traitor. She tells General Marcus "I'll attack" and tells General Lucius "I'll retreat." Her messengers carry contradictory orders and nobody can verify what she told someone else.
It gets worse. The messengers themselves might be intercepted. A traitor could forge messages. And when Marcus asks Lucius "what did Theodora tell you?", Lucius could lie about that too, if Lucius is also a traitor.
The loyal generals don't know who the traitors are. They don't know how many traitors there are. They only know the upper bound on how many there could be. And they need to agree on a plan anyway.
Three Generals, One Traitor, No Solution
Lamport's first result was an impossibility proof, and it's one of those results that seems obvious once you see it but nobody had formalized it before.
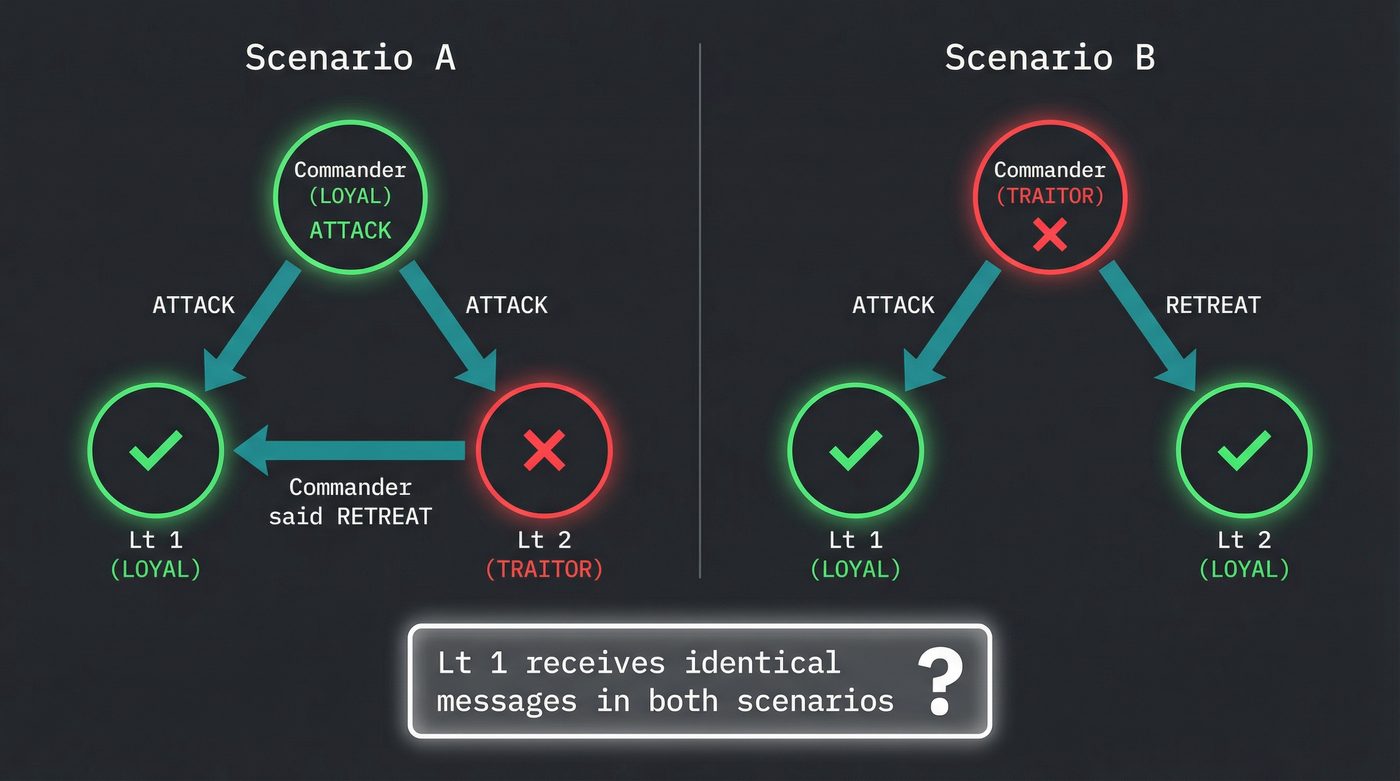
Take the simplest case. Three generals. One is a traitor. Two are loyal.
Scenario A: The commanding general is loyal and sends "ATTACK" to both lieutenants. But Lieutenant 2 is the traitor. Lieutenant 2 tells Lieutenant 1: "The commander told me RETREAT."
Lieutenant 1 has received "ATTACK" from the commander and a claim of "RETREAT" from Lieutenant 2. Which one is lying?
Scenario B: The commanding general is the traitor. He sends "ATTACK" to Lieutenant 1 and "RETREAT" to Lieutenant 2. Both lieutenants are loyal.
Lieutenant 1 got "ATTACK." Lieutenant 2 got "RETREAT." They relay what they received to each other. Lieutenant 1 hears Lieutenant 2 say "I got RETREAT." From Lieutenant 1's perspective, this looks exactly like Scenario A. There is no way to distinguish "the commander is honest and Lieutenant 2 is lying" from "the commander is the traitor."
That's the impossibility. With three generals and one traitor, a loyal general cannot determine the truth. There is no algorithm, no protocol, no amount of additional message-passing that fixes this. It's not an engineering problem. It's a mathematical impossibility. Lamport proved it with a formal reduction, but the intuition is this: with only three parties, a single traitor creates enough ambiguity to make consensus undecidable.
I remember first reading this proof and feeling genuinely unsettled. Not because the math was hard — because the implication was enormous. If three nodes can't agree when one is faulty, what hope does any real system have?
Quite a lot, actually. You add more generals.
The Threshold: 3f + 1
The core result of the paper: to tolerate f traitors, you need at least 3f + 1 generals.
With 4 generals, you can handle 1 traitor. With 7, you can handle 2. With 10, you can handle 3.
Why 3f + 1 and not 2f + 1? Because a traitor doesn't just go silent — a traitor actively lies. In the three-general case, the single traitor can make themselves look loyal and a loyal general look traitorous. You need enough honest voices to outvote the dishonest ones even when the dishonest ones are coordinating their lies. Two-to-one isn't enough.
The algorithm Lamport described works in rounds. Each general sends their value to every other general. Then each general relays what they received to every other general. Then they do it again. After f + 1 rounds of message exchange, the loyal generals can use majority voting to determine the true consensus, because the traitors can't fabricate enough consistent lies to overwhelm the honest majority.
The message complexity is brutal. With n generals and f rounds, you're looking at O(n^f+1) messages. For 7 generals tolerating 2 traitors, that's 7^3 = 343 messages just to agree on a single binary decision.
Not cheap. But correct.
Replace "Generals" with "Servers"
Here's where a 1982 thought experiment becomes your production problem.
Replace "generals" with servers in a distributed system. Replace "traitors" with faulty nodes. Replace "attack or retreat" with "commit or abort this transaction." Replace "messengers" with network packets. The problem is identical.
But there's a distinction that matters enormously: not all faults are Byzantine.
A crash fault is a node that stops responding. It falls over. It's gone. You know it's gone because it stopped sending heartbeats. A crashed node is honest — it just isn't there anymore.
A Byzantine fault is a node that keeps running but behaves arbitrarily. It might send wrong data. It might send different data to different peers. It might respond to some requests and ignore others. It might be compromised by an attacker. It might have a firmware bug that corrupts checksums. The defining characteristic: you cannot distinguish a Byzantine-faulty node from a functioning one by looking at any single message.
Most real distributed systems only handle crash faults. Raft, Paxos, ZooKeeper, etcd — they assume nodes are either honest or dead. That assumption buys you a much cheaper threshold: 2f + 1 nodes to tolerate f crash faults. A 3-node Raft cluster handles 1 failure. A 5-node cluster handles 2. No rounds of relay messages. No O(n^f) overhead.
That's why your Kubernetes control plane runs 3 or 5 etcd nodes and calls it a day. Crash fault tolerance is practical. Byzantine fault tolerance is a completely different beast.
Where Byzantine Tolerance Actually Matters
If crash faults cover most real systems, when do you actually need BFT?
When the nodes don't trust each other.
Aircraft flight control. The Space Shuttle ran four identical flight computers executing the same code, with a fifth backup running independently written software. The four primary computers used Byzantine-tolerant voting to reach consensus on control surface positions. If one computer had a hardware fault that made it output garbage (not crash — output wrong values), the other three could outvote it. Four computers, one potential Byzantine fault: 3(1) + 1 = 4. The math checked out at 17,000 miles per hour.
NASA didn't trust their own hardware to fail cleanly, and they were right. A stuck bit in a sensor input register doesn't crash the computer. It makes the computer confidently wrong. That's a Byzantine fault. If you've ever asked an LLM a question and watched it cheerfully invent a function that doesn't exist, complete with documentation, parameter names, and a confident "this should work" — congratulations, you've met a Byzantine fault. The model didn't crash. It didn't return an error. It returned something that looks exactly like a correct answer and is wrong in ways you can only catch by checking. Same failure mode, different millennium.
Blockchain. Bitcoin's real innovation was extending Byzantine consensus to an open, permissionless network where the number of participants is unknown, anyone can join or leave at any time, and there is no trusted setup phase. Classical BFT assumes you know who the N nodes are. Satoshi's proof-of-work mechanism works without that assumption — at the cost of making consensus expensive enough that sybil attacks (spinning up fake nodes) become economically irrational.
I have opinions on this. Braces for Bitcoin Bro Onslaught.
Proof of work is the most expensive consensus mechanism ever devised by humans, and I don't mean that as a compliment. It works — the Bitcoin network has maintained consensus since January 3, 2009 without a central authority — but it works by burning real electricity, at scale, in the real world, to prove that nobody has enough money to rewrite the last hour of history. The energy cost isn't a bug or an efficiency problem we haven't fixed yet; it is the security model. You can't have the consensus without the burn. Any proposal to make Bitcoin "greener" without switching consensus mechanisms is a proposal to make it insecure.
The scale is hard to grasp until you put it in real units. The Cambridge Bitcoin Electricity Consumption Index has the network sitting somewhere around 150 TWh/year — comparable to the entire annual electricity consumption of Argentina, or roughly 0.5% of global electricity generation. That moves week to week with price and mining difficulty, but the order of magnitude has been stable for years. Lamport's generals would have been appalled — not by the waste, but by the realisation that the only thing the traitors respect is a bonfire large enough to see from orbit. Elegant in theory. Absurd in practice. The engineering equivalent of securing your house by building it out of solid gold so thieves can't carry the walls away.
PBFT: Making It Practical
For 17 years after Lamport's paper, Byzantine fault tolerance was a theoretical curiosity. The message complexity was too high. The round count was too deep. Nobody was running it in production outside of aerospace.
Then in 1999, Miguel Castro and Barbara Liskov published "Practical Byzantine Fault Tolerance." The title was the point.
A quick aside on Liskov, because if you've been writing object-oriented code at any point in the last forty years you owe her a beer. Barbara Liskov is the L in SOLID — the Liskov Substitution Principle, the rule that says if Cat is a subtype of Animal, then anywhere your code expects an Animal you should be able to pass a Cat and have it just work. That sounds obvious now. It wasn't. Liskov formalised it in a 1987 keynote at OOPSLA, and the principle is now baked into how every typed OO language thinks about inheritance. She also designed CLU, the language that pioneered abstract data types, iterators, and exception handling — basically every feature you take for granted in Python, Java, Ruby, and Rust. She won the Turing Award in 2008. By the time she co-wrote PBFT, she was already one of the most influential computer scientists of the twentieth century. So when Liskov puts her name on a paper called "Practical Byzantine Fault Tolerance," people listen.
PBFT works in three phases for each client request:
Pre-prepare. The primary node (a designated leader) assigns a sequence number to the request and broadcasts a pre-prepare message to all replicas. This is the proposal: "I think this request should be number 47."
Prepare. Each replica validates the pre-prepare (is the sequence number right? does it conflict with anything?) and broadcasts a prepare message to all other replicas. When a replica has seen 2f + 1 matching prepare messages including its own, it knows that enough honest nodes agree on the ordering.
Commit. Each replica that has enough prepare messages broadcasts a commit message. When a replica has received 2f + 1 matching commit messages, it executes the request and replies to the client.
Three network round-trips per request. O(n^2) messages per consensus decision. For a system with, say, 7 nodes tolerating 2 Byzantine faults, that's 49 messages per request. Expensive compared to Raft's single round-trip, but actually feasible for the first time.
Castro and Liskov demonstrated PBFT running a replicated NFS file system with only 3% overhead compared to an unreplicated server. That number changed the conversation. BFT went from "theoretically possible but never do it" to "expensive but maybe worth it."
Modern permissioned blockchains — Hyperledger Fabric, Tendermint — are direct descendants of PBFT. They don't burn electricity. They run three-phase commit among a known set of validators. Lamport's generals, finally practical, 17 years later.
The Two Generals Problem (It's Different)
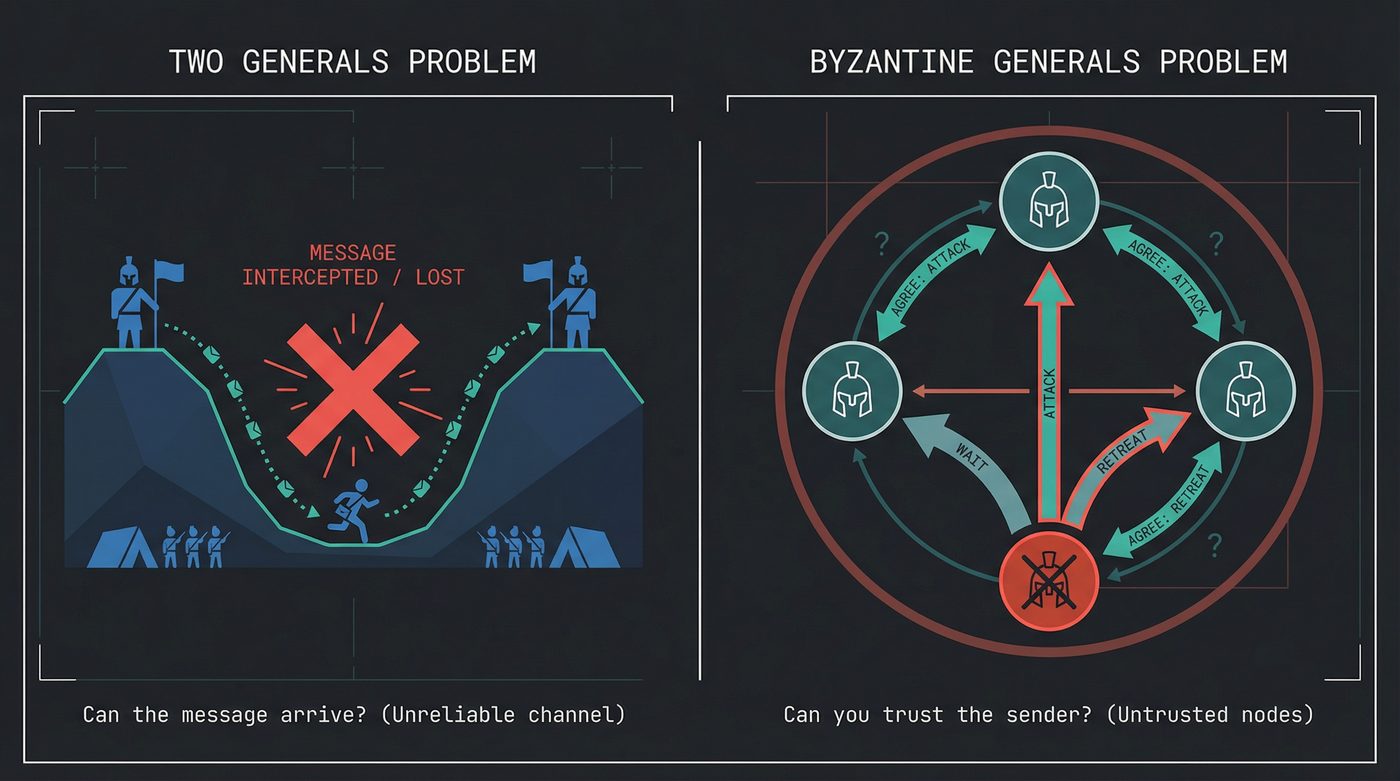
There's a related problem that people confuse with the Byzantine Generals Problem, and it predates Lamport's paper by seven years. It's called the Two Generals Problem, and it's about something fundamentally different.
Two generals on opposite sides of a valley need to coordinate an attack on the army between them. They can only communicate by sending messengers through the valley — but messengers can be captured. The communication channel is unreliable.
General A sends a message: "Attack at dawn." Did General B receive it? A doesn't know. B sends an acknowledgment back: "Got it, attacking at dawn." Did A receive the acknowledgment? B doesn't know. A could send an acknowledgment of the acknowledgment. But did that arrive?
This is an infinite regress. No finite number of messages can guarantee both generals know the other received confirmation. The Two Generals Problem is provably unsolvable for guaranteed agreement over an unreliable channel.
The distinction: the Byzantine Generals Problem is about trust — nodes might lie. The Two Generals Problem is about delivery — messages might not arrive. Different failure mode, different impossibility.
And if the Two Generals Problem sounds familiar, it should. I wrote about it in the TCP post. TCP's three-way handshake is an engineering compromise on the Two Generals Problem. It doesn't solve the impossibility — it manages the risk to an acceptable level. SYN, SYN-ACK, ACK. Both sides are now reasonably confident the other is there. Not certain. Confident enough to send data.
Every TCP connection you've ever opened is an admission that guaranteed consensus over unreliable links is impossible, papered over with sequence numbers and retransmission timers.
The Man Behind the Curtain
Leslie Lamport deserves some attention, because the scope of his contributions to computer science is staggering and most working programmers couldn't pick him out of a lineup.
He invented the Byzantine Generals Problem formulation. He also invented Paxos — the consensus algorithm that underpins Google's Chubby lock service, Apache ZooKeeper, and most serious distributed systems built between 2000 and 2015. He formalized the concept of "happens-before" ordering in concurrent systems, which is the theoretical foundation for every vector clock and causal consistency model in use today. He created the concept of sequential consistency. He wrote the bakery algorithm for mutual exclusion.
Oh, and he wrote LaTeX. Not the underlying typesetting engine — that's TeX, built by Donald Knuth in 1978 because he was unhappy with the typesetting of the second volume of The Art of Computer Programming. TeX is the engine. LaTeX is the layer on top that Lamport added in 1984: document structure, sections, references, bibliographies, the macros that make TeX usable by humans who don't want to hand-tune every kerning decision. Together they're the system used to write nearly every academic paper in mathematics, physics, and computer science for the last 40 years. Lamport built the human-friendly layer over Knuth's typesetting masterpiece. Side project energy from one of the most cited computer scientists alive, on top of side project energy from another of them.
Lamport won the Turing Award in 2013 — computer science's Nobel Prize — and the citation specifically mentioned his work on distributed systems. The man formalized how we think about time, ordering, and agreement in systems where no global clock exists. If you've ever used a system that replicates data across machines, you're standing on his shoulders.
He is, as of this writing, 85 years old and still publishing.
Why You Should Care
Every time you've deployed a service with more than one replica, you've commanded Lamport's generals. Every Redis cluster, every Postgres replica set, every Kubernetes control plane — five generals on five hilltops, messengers riding between them, and you trying to figure out who to trust. The moment data exists in more than one place and needs to agree, you're in Lamport's territory.
Your distributed cache has nodes. If one returns stale data while the others have fresh data, that's a consistency fault. If your consensus protocol for cache invalidation only handles crash faults (node disappears) and not Byzantine faults (node returns wrong data), then a corrupted cache node can silently serve garbage while appearing healthy. Is it likely? No. Is it possible? Yes. Understanding the distinction tells you what your system can and can't survive.
The CAP theorem tells you that you can't have consistency, availability, and partition tolerance simultaneously. The Byzantine Generals Problem tells you something more specific: how many nodes you need to achieve consistency when nodes might be faulty, and what kinds of faults change the answer.
Sync primitives handle consensus when threads share memory on a single machine. Distributed consensus handles it when they don't. The problems are cousins. Mutexes are the easy case — a single source of truth, the memory bus, arbitrates. Networks have no such luxury.
Every time you set a replication factor, choose a quorum size, or configure the number of etcd nodes in your cluster, you're making a decision that traces directly back to a 1982 paper about Byzantine generals. The math hasn't changed. 3f + 1 for Byzantine faults. 2f + 1 for crash faults. Everything else is engineering around those constraints.

Further Reading
- The Byzantine Generals Problem (Lamport, Shostak, Pease, 1982) — The original paper. Lamport's writing is remarkably clear for an academic paper from 1982. Read it.
- Practical Byzantine Fault Tolerance (Castro, Liskov, 1999) — The paper that made BFT feasible. The performance results are the key section.
- The Part-Time Parliament (Lamport, 1998) — Lamport's Paxos paper, written as an allegory about a Greek parliament. Famously confusing and famously brilliant.
- Bitcoin: A Peer-to-Peer Electronic Cash System (Nakamoto, 2008) — The whitepaper that applied Byzantine consensus to a trustless network. Nine pages that launched a trillion-dollar industry.
- Time, Clocks, and the Ordering of Events in a Distributed System (Lamport, 1978) — The "happens-before" paper. If you read one Lamport paper beyond the Byzantine Generals, make it this one.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri once tried to explain the Byzantine Generals Problem to a non-technical friend using salt shakers at a restaurant and got asked to leave. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.