The Bug That Won't Die
Buffer Overflows: From Morris's Worm to Your Last CVE
Reading time: ~15 minutes
In 1988, a Cornell graduate student named Robert Tappan Morris wrote a few thousand lines of C that crashed roughly 10% of the internet (the exact percentage depends on what you count as "the internet" in 1988 — estimates of affected machines range from 6,000 to 60,000 out of a network of perhaps 60,000 hosts).
The worm actually exploited three separate vectors — a sendmail DEBUG command that let you pass a program to run, an rsh/rexec trust relationship that let a compromised host jump to others, and a buffer overflow in the fingerd daemon. The last one is the one relevant here, and it's the one that made buffer overflows famous. fingerd used gets() — a function that reads input into a buffer without checking how much space is left. Morris's worm sent more data than the buffer could hold. The extra bytes spilled past the buffer, overwrote the return address sitting on the stack, and redirected execution to his payload. The function returned — but not to where it was supposed to.
That was 38 years ago. Historically, roughly 70% of Microsoft's security vulnerabilities have been memory safety issues. The same class of bug. The same fundamental mechanic. Three decades of mitigations, and we're still not done.
The Stack Frame: Where Functions Live
Before you can understand how a buffer overflow works, you need to see what a function call looks like in memory. Not the abstraction — the actual layout on the stack.
When your program calls a function, the CPU pushes a stack frame onto the call stack. This frame contains everything the function needs to execute and, critically, everything it needs to return.
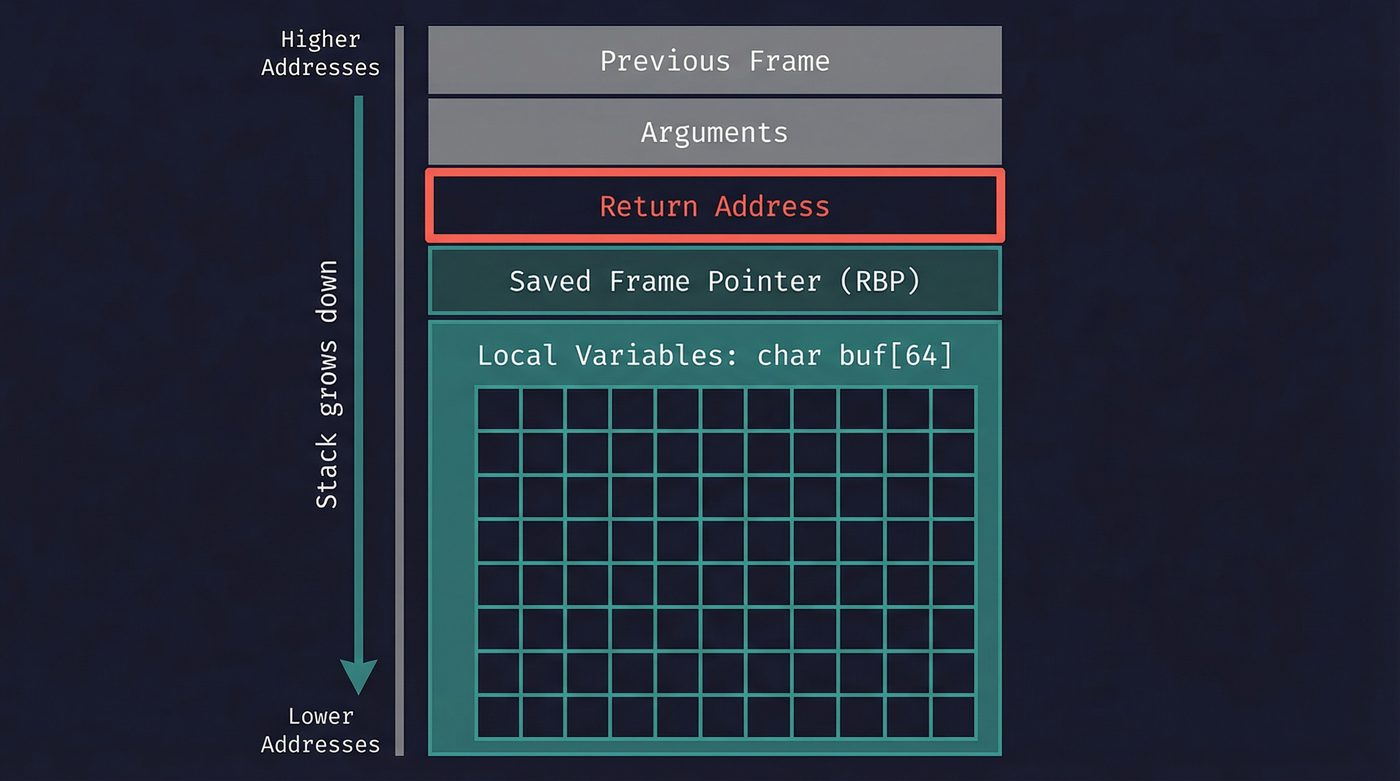
Here's the layout, from high memory to low:
- Arguments passed by the caller
- Return address — the instruction to jump back to when this function finishes
- Saved frame pointer — the previous function's base pointer, so the stack can be unwound
- Local variables — your buffers, counters, pointers, whatever the function allocates
The return address is the critical piece. It's a pointer back to the calling function — the exact instruction to resume after this function returns. The CPU trusts this address. When the function hits ret, it pops this value off the stack and jumps there. No questions asked.
Local buffers grow upward toward higher addresses. The return address sits above them at a higher address. That spatial relationship is the whole vulnerability.
The Classic Stack Smash
In 1996, a hacker named Aleph One published "Smashing the Stack for Fun and Profit" in Phrack magazine, issue 49. It was the paper that taught a generation of security researchers (and attackers) exactly how buffer overflows work. It's still worth reading today — remarkably clear, especially for a 1996 zine article.
Here's the vulnerable code, stripped to its essentials:
#include <string.h>
void vulnerable(char *input) {
char buf[64];
strcpy(buf, input); // no bounds check. copies until null terminator.
}
int main(int argc, char **argv) {
vulnerable(argv[1]);
return 0;
}
strcpy copies bytes from input into buf until it hits a null terminator. It doesn't know — and doesn't care — how big buf is. If input is 200 bytes, strcpy will faithfully copy all 200 bytes. The first 64 land in the buffer. The next 8 overwrite the saved frame pointer. The next 8 overwrite the return address. The rest keep going, trampling whatever's above.
Let me walk through exactly what happens in memory.
Before the overflow, the stack looks clean:
[ buf (64 bytes) ][ saved RBP (8) ][ return addr (8) ][ caller's frame ]
After strcpy with a 200-byte input:
[AAAAAAAAAAAAAAAAAAA][AAAAAAAA][0xdeadbeef][ ... more A's ... ]
64 bytes 8 bytes attacker's
address
The attacker fills the buffer with padding (traditionally 0x41, the letter A — you'll see it in every exploit writeup), then carefully places a chosen address where the return address should be. When vulnerable() returns, the CPU pops 0xdeadbeef off the stack, sets the instruction pointer to that address, and starts executing whatever lives there.
The function returned. To the attacker's code.
This is the moment it clicks. The return address isn't protected. It's not in a special register. It's sitting right there on the stack, mixed in with your local variables, separated by nothing. One careless write and it's gone.
I remember the first time I traced through this in a debugger — watching rip jump to an address I'd written into a buffer. I knew the theory before that, but seeing the instruction pointer obey you is a different thing entirely. It's the moment the abstraction of "control flow" stops being abstract.
Why C Is the Way It Is
C doesn't check buffer boundaries. Not at compile time, not at runtime. strcpy, strcat, gets, sprintf — they all write until they're done, without asking how much room there is.
This wasn't an oversight. Dennis Ritchie and Ken Thompson designed C in the early 1970s on a PDP-11 with 24KB of RAM. Bounds checking costs cycles. On a machine that slow, with that little memory, the tradeoff made sense: trust the programmer, go fast.
gets() was the worst offender. It reads from stdin into a buffer with no length parameter at all. There's literally no way to use it safely. The C11 standard finally removed it in 2011 — more than three decades after K&R C standardised it, and longer still if you count Ritchie's earlier work. The man page for gets on Linux still reads: "Never use this function." That's not advice. That's the man page.
The safer alternatives exist now — snprintf, fgets, and OpenBSD's strlcpy/strlcat (which glibc finally adopted) — but they're opt-in. I'm deliberately leaving strncpy off that list, even though it's the one every C textbook reaches for: strncpy will silently not null-terminate its output if the source is exactly as long as the buffer, which trades one footgun for another. The unsafe versions still compile without a warning on most toolchains (though GCC and Clang will warn about gets specifically). The minefield is well-marked, but nobody fenced it off.
Shellcode: What Goes in the Buffer
Overwriting the return address is half the attack. The other half: what do you point it at?
In the classic scenario, the attacker puts machine code directly into the buffer, then points the return address back at the buffer itself. The CPU jumps to the buffer and starts executing the attacker's bytes as instructions.
The canonical payload spawns a shell — /bin/sh — giving the attacker an interactive command line with whatever privileges the vulnerable program had. That's why it's called shellcode. Not because it's written in shell script, but because the endgame is a shell.
Here's what classic x86 shellcode looks like in the buffer:
[ NOP sled (0x90 0x90 0x90 ...) ][ shellcode ][ return addr → buf ]
The NOP sled is a long sequence of no-op instructions (0x90 on x86). The attacker doesn't need to hit the exact start of their shellcode — they aim the return address somewhere into the NOP sled, and the CPU slides down the no-ops until it reaches the payload. Crude but effective. Aiming doesn't need to be precise when your target is 200 bytes wide.
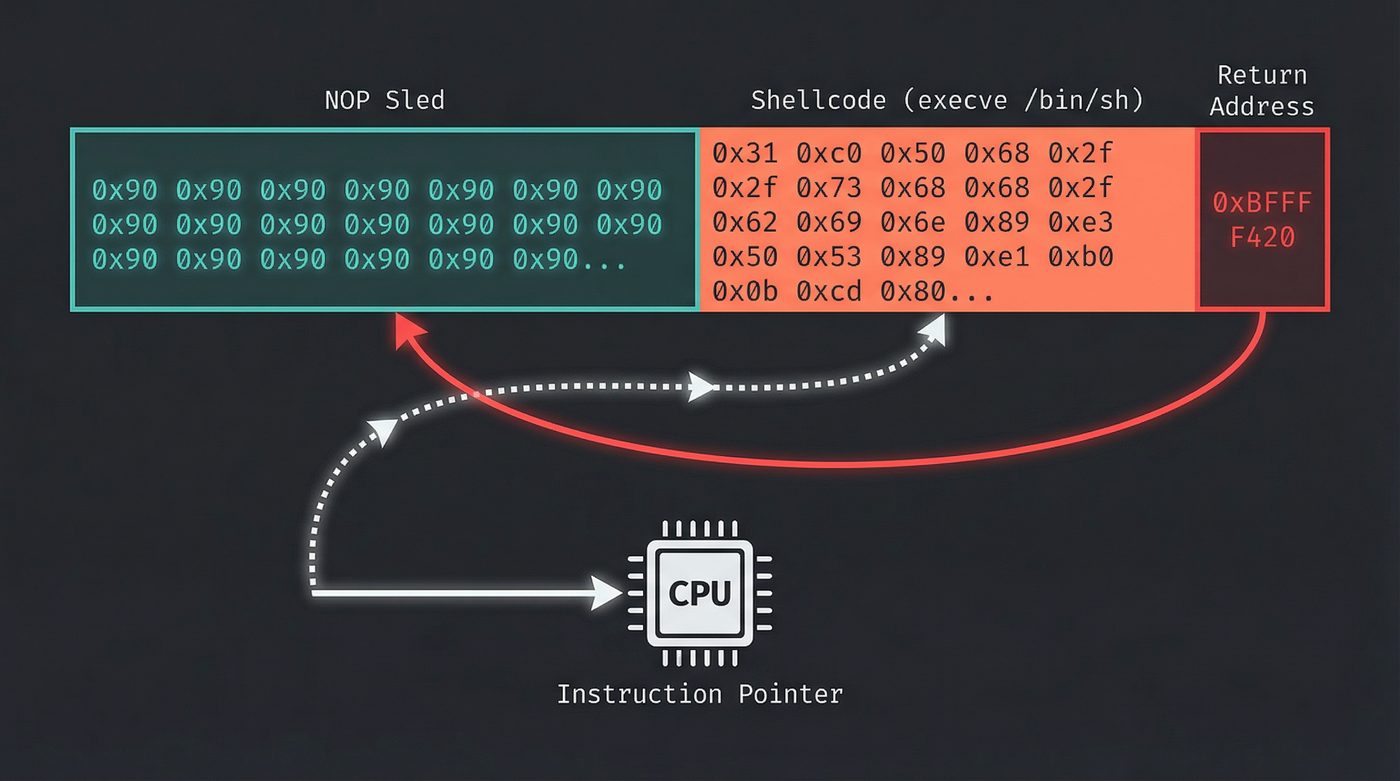
The shellcode itself is hand-crafted assembly — a few dozen bytes that set up the right registers and call execve("/bin/sh", NULL, NULL). Writing shellcode is a dark art. It can't contain null bytes (because strcpy stops at nulls). It has to be position-independent (because you don't know exactly where the buffer will be). It has to be short (because buffers are small). The constraints produce some of the most creative assembly programming you'll ever read.
The Hardware Fights Back: NX Bit
The buffer overflow worked because the CPU didn't distinguish between "data I'm storing" and "code I should execute." Memory was memory. If the instruction pointer landed there, the CPU ran it.
The fix was architectural. Intel (XD bit) and AMD (NX bit — No eXecute) added a permission bit to each page table entry. The operating system marks the stack — and the heap — as non-executable. If the instruction pointer lands on a page marked NX, the CPU raises a hardware fault. The program crashes instead of being exploited.
This was deployed widely starting around 2004 (Windows XP SP2, Linux with exec-shield). It killed the classic stack smash dead. You can write all the shellcode you want into a buffer — the CPU won't run it.
Problem solved. For about three years.
The Attacker's Masterpiece: Return-Oriented Programming
In 2007, Hovav Shacham published "The Geometry of Innocent Flesh on the Bone: Return-into-libc without Function Calls." The title is ridiculous. The technique is brilliant. The precursor — plain "return-to-libc," where you overwrite the return address to point at an existing libc function like system() — had been kicking around since the late 1990s (Solar Designer described it publicly in 1997). Shacham's contribution was generalising it: showing that you don't need whole libc functions, you can chain tiny fragments of existing code, and proving the result is Turing-complete.
The insight: you don't need to inject new code if you can reuse existing code.
Every program links against shared libraries — libc, libm, the dynamic linker. These libraries contain thousands of small instruction sequences, each ending with a ret instruction. Shacham called these sequences gadgets.
A gadget might be:
pop rdi ; load a value from the stack into rdi
ret ; return (jump to the next address on the stack)
Or:
mov rax, [rdi] ; load a value from memory
ret
Each gadget does one tiny thing, then returns. And ret means "pop the next address off the stack and jump there." The attacker doesn't overwrite the return address with one address — they overwrite it with a chain of addresses. Each address points to a gadget. Each gadget executes its few instructions, hits ret, and pops the next gadget's address.
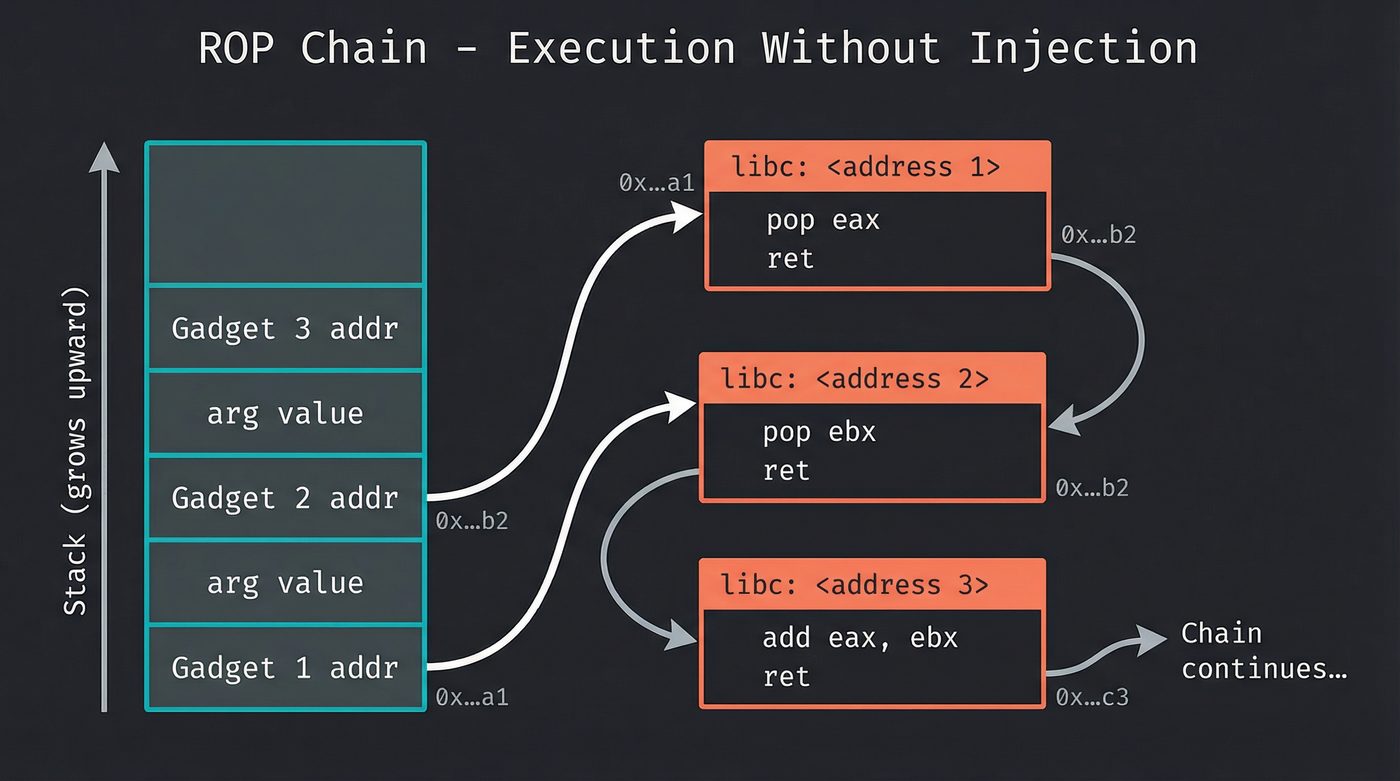
The stack becomes a program. Each entry is an instruction — not machine code, but a pointer to a fragment of legitimate code that's already in memory, on an executable page, blessed by the NX bit. The CPU is executing real, signed, legitimate instructions from libc. It doesn't know those instructions are being chained together by an attacker who rewired the stack.
Shacham proved that ROP is Turing-complete. With enough gadgets, you can perform arbitrary computation. Conditionals, loops, memory access, system calls — all using existing code fragments, stitched together by a corrupted stack.
I find this genuinely beautiful. Shacham didn't design a new language the way language designers normally do — start with a grammar, pick clean primitives, build the abstractions upward. He was handed a bag of accidental atoms. Gadgets are not designed; they're side effects of how compilers happen to emit machine code — fragments of other people's intentions, each one ending in ret because the compiler needed to return from a function. The shapes are irregular. The vocabulary is whatever the binary happened to contain. And from that pile of arbitrary, unrelated debris, he proved you can build a Turing-complete computational substrate. It's like proving you can write any poem using only words you find on receipts in the bottom of your bag. The grammar isn't the point — the constraint is. He built a language out of garbage and made it work.
ASLR: Hiding the Map
ROP requires knowing where the gadgets are. If libc always loads at address 0x7ffff7a00000, the attacker can hardcode their gadget addresses. The chain is static, reliable, repeatable.
Address Space Layout Randomization breaks that assumption. ASLR randomizes where the stack, heap, shared libraries, and the program itself are loaded in virtual memory. Every time the program starts, everything is at a different address.
With full ASLR enabled (and PIE — Position-Independent Executables), the attacker can't predict where libc will be. Their ROP chain points to the wrong addresses. The exploit crashes instead of popping a shell.
ASLR isn't perfect. On 32-bit systems, the randomization entropy is low enough to brute-force — there are only so many possible base addresses. Information leak vulnerabilities can reveal library addresses, letting the attacker defeat ASLR by reading before writing. But ASLR massively raises the cost of exploitation, especially on 64-bit systems where the address space is vast.
Stack Canaries: The Tripwire
A different approach: instead of hiding addresses, detect the overwrite itself.
Stack canaries (named after the canary in the coal mine) place a random value between the local variables and the saved return address. Before the function returns, the compiler inserts a check: is the canary still intact? If something overwrote the buffer far enough to reach the return address, it had to pass through the canary first. The canary value will be wrong. The program terminates immediately — __stack_chk_fail, SIGABRT, crash.
[ buf (64 bytes) ][ CANARY ][ saved RBP ][ return addr ]
The canary is generated randomly at program startup and stored in a location the attacker can't easily read (typically the thread-local storage area, pointed to by fs on x86-64). The compiler inserts the canary automatically when you compile with -fstack-protector (GCC, Clang). Most distributions enable this by default now.
The canary doesn't prevent the overflow. It prevents the exploitation. The buffer still gets trashed. But the program dies before the corrupted return address can be used.
The Modern Mitigation Stack
No single defense is enough. Modern systems layer them:
- NX/DEP — non-executable stack and heap. Hardware-enforced.
- ASLR — randomized memory layout. OS-enforced.
- Stack canaries — corruption detection. Compiler-enforced.
- RELRO (Relocation Read-Only) — makes the Global Offset Table read-only after linking. Prevents GOT overwrite attacks.
- PIE (Position-Independent Executables) — allows the main binary to be loaded at a random address, not only shared libraries.
- CFI (Control-Flow Integrity) — restricts indirect calls to valid targets. Prevents ROP gadgets from chaining through arbitrary code.
Defense in depth. Each layer stops a different class of attack. Each layer was invented because someone found a way around the previous one. It's an arms race, and the defenders are winning — slowly, expensively, and never completely.
I'm glossing over the details of RELRO, PIE, and CFI here. Each one deserves its own section, but the buffer overflow post is about the stack smash and its direct countermeasures. The mitigation list matters less than understanding why it keeps growing.
Heap Overflows: Same Disease, Different Organ
The stack isn't the only target. The heap — where malloc and friends allocate memory (I wrote about this in detail in post 10) — has its own class of overflow bugs.
Heap overflows are harder to exploit but not fundamentally different. Instead of overwriting a return address, you overwrite heap metadata — the bookkeeping structures that the allocator uses to track free and allocated chunks. Corrupt those structures, and you can trick the allocator into writing an arbitrary value to an arbitrary address the next time free() or malloc() is called. That's called a write-what-where primitive, and it's as dangerous as it sounds.
Use-after-free: free a chunk of memory, then keep using the pointer. If the allocator hands that memory to someone else, the old pointer now points into someone else's data. Modify it, and you're corrupting a different object. This is the most common heap vulnerability in modern browsers.
Double-free: free the same pointer twice. This corrupts the allocator's free list. Depending on the allocator, this can lead to two different allocations returning the same memory — again, a recipe for corruption.
These are uglier and harder to exploit than the classic stack smash. But they're equally fatal. Heartbleed (2014) was a heap buffer over-read in OpenSSL — a missing bounds check allowed attackers to read up to 64KB past the end of a buffer, leaking private keys, session tokens, and passwords from server memory. The fix was two lines of code. The damage was incalculable.
Why Rust Matters (And Why It's Not About Performance)
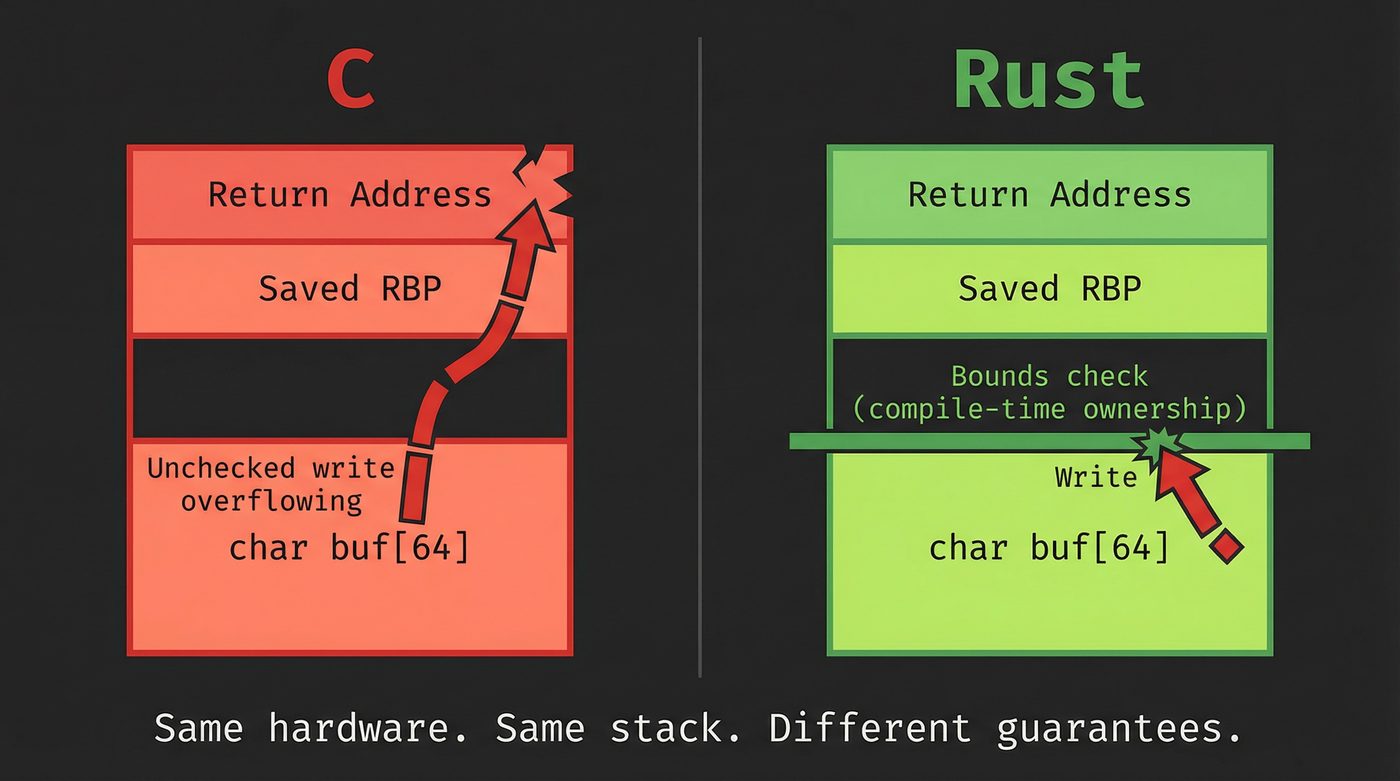
The argument for Rust (and other memory-safe languages) isn't performance. It isn't ergonomics. It isn't the type system or the package manager, though those are nice.
It's this: safe Rust cannot produce a buffer overflow.
The ownership and borrowing system prevents writes past the end of an array at compile time. Not at runtime (though runtime bounds checks exist too) — at compile time. The class of bug that Robert Morris exploited in 1988, that Aleph One documented in 1996, that produced Heartbleed in 2014, that accounts for 70% of Microsoft's CVEs — safe Rust eliminates it by construction. (Not all memory-safety issues — unsafe blocks exist, and logic errors are still your problem — but the specific class of spatial-safety bugs that drove most of those numbers, yes.)
You can still write unsafe Rust. When you do, you're opting back into manual memory management, and the overflow potential comes back. But unsafe is a keyword you have to type deliberately. It shows up in code review. It's auditable. The default is safe.
I wrote about Rust's SIMD intrinsics in post 12 — even those low-level operations can be wrapped in safe abstractions. The language is designed so that the safe/unsafe boundary is explicit, narrow, and auditable.
This is the real argument for memory-safe languages. Not "Rust is faster than C" (it's comparable). Not "Rust has better tooling" (arguable). The argument is: we've been making the same mistake for 38 years, and we've built a language that makes it structurally impossible.
The Bug That Won't Die
In February 2024, the White House Office of the National Cyber Director published a report calling for a shift to memory-safe languages. Not legally binding — it's a policy advisory, not a law — but when the executive branch tells the federal software supply chain that memory-unsafe languages are the problem, procurement teams start paying attention. The reason was straightforward: after decades of mitigations, training, static analysis, fuzzing, and code review, buffer overflows and related memory safety bugs still account for the majority of critical vulnerabilities in systems software.
Here's the obligatory tick tock:
- 1988: Morris Worm.
gets()infingerd. 10% of the internet down. - 1996: Aleph One publishes "Smashing the Stack for Fun and Profit." The technique is now public knowledge.
- 2001: Code Red worm. Buffer overflow in Microsoft IIS. 359,000 hosts in 14 hours.
- 2003: SQL Slammer. Buffer overflow in SQL Server. Doubled every 8.5 seconds. Infected 75,000 hosts in 10 minutes.
- 2014: Heartbleed. Buffer over-read in OpenSSL. Every TLS server running the affected versions leaked memory.
- Historically: roughly 70% of Microsoft's security vulnerabilities. 70% of Chrome's. Memory safety.
Same bug. Same stack frame. Same spatial relationship between a buffer and a return address — or a heap chunk and its metadata.
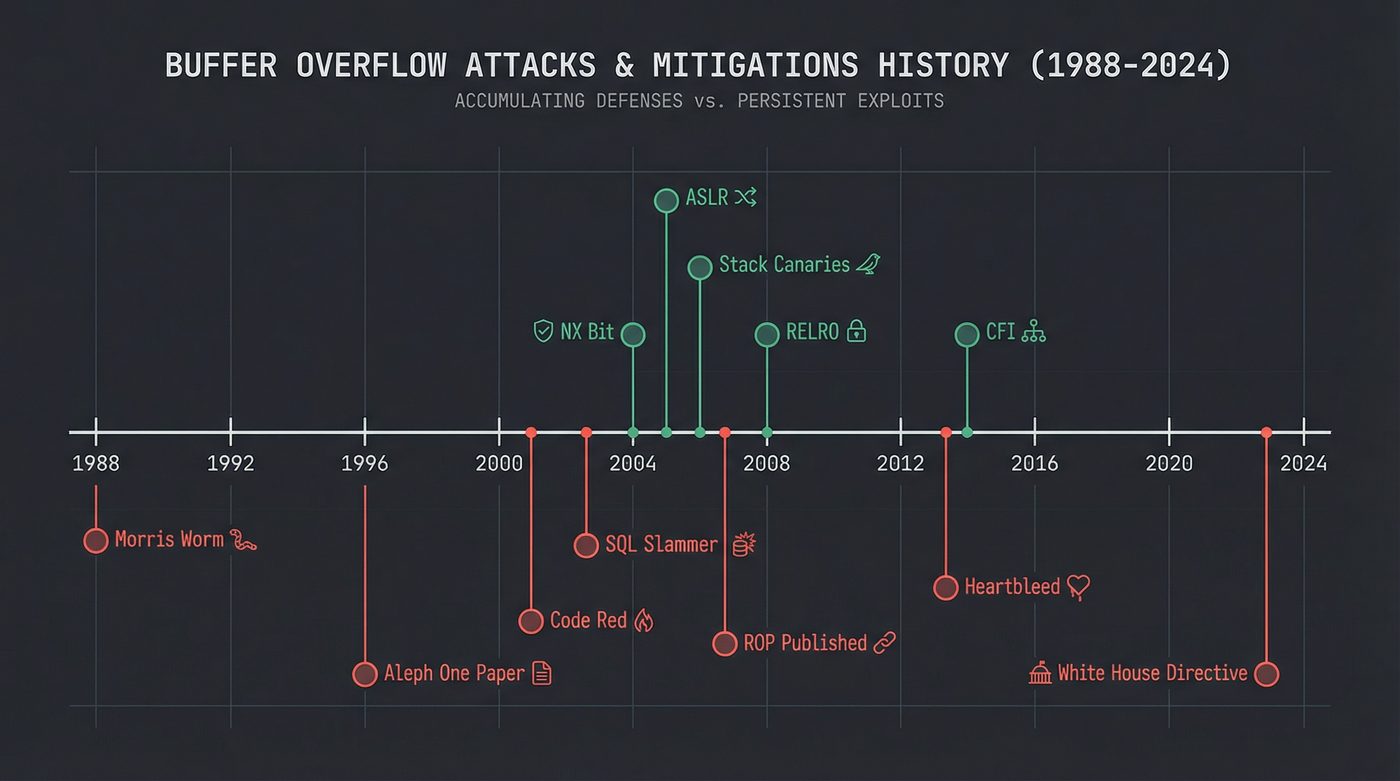
The mitigations work. They make exploitation harder, more expensive, less reliable. But they don't eliminate the root cause. The root cause is writing past the end of a buffer in a language that lets you.
Understanding how a buffer overflow works — the stack frame, the return address, the overwrite, the redirect — isn't about learning to attack. It's about understanding why the defenses exist, why they're layered the way they are, and why the industry is slowly, painfully moving toward languages that prevent the bug entirely.
The instruction pointer doesn't care about your intentions. It goes where the return address tells it.
Make sure the return address is yours.
Further Reading
- malloc Is Not Free (post 10) — How heap allocation works, and why heap overflows are a different beast.
- How Your Python Code Actually Runs (post 11) — The execution pipeline, stack frames, and how the CPU processes instructions.
- SIMD: The Instructions Your CPU Has Been Hiding (post 12) — Safe Rust wrappers around unsafe intrinsics.
- What Your RAM Actually Does (post 15) — Stack vs. heap in physical memory.
- Smashing the Stack for Fun and Profit — Aleph One (1996) — The original paper. Still the best introduction to stack smashing.
- Morris Worm — Wikipedia — History and technical details of the 1988 worm.
- Google Project Zero Blog — Modern vulnerability research, including numerous buffer overflow and memory safety writeups.
- The Geometry of Innocent Flesh on the Bone — Hovav Shacham (2007) — The ROP paper. Dense but foundational.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri has stared at enough corrupted stack frames to develop a Pavlovian response to the hex sequence 0x41414141. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.