The Paper That Broke Your Database Assumptions
How Amazon's Shopping Cart Launched the NoSQL Movement
Reading time: ~14 minutes
In 2007, Amazon published a paper about their shopping cart. Not the frontend. Not the recommendation engine. The database behind the "Add to Cart" button.
The paper's thesis was deceptively simple: for a shopping cart, availability matters more than consistency. If the network partitions between two data centres and a customer adds an item, you accept the write on both sides and reconcile later. A customer seeing a duplicate item in their cart is mildly annoying. A customer getting an error page during checkout costs you real money.
This paper — "Dynamo: Amazon's Highly Available Key-Value Store" — launched the NoSQL movement. Not because it invented new data structures. Because it made a business argument for throwing away the thing every database developer took for granted: strong consistency.
The Business Case for Broken Promises
Amazon's CTO Werner Vogels had a specific requirement: every customer must always be able to add items to their cart. Not "99.99% of the time." Always. The system should accept writes even during network failures, even during data centre outages, even during rolling deployments.
Traditional relational databases can't do this. A Postgres cluster with synchronous replication will refuse writes if it can't confirm the replica got the data. That's the correct behaviour if you're a bank. It's the wrong behaviour if you're a shopping cart.
Vogels and the Dynamo team made an explicit choice. In the CAP theorem framing I covered in post 29, they chose AP — availability and partition tolerance — over consistency. They wrote it down. They published it. And they showed that for their use case, it was the right call.
The numbers backed it up. Amazon's internal SLA was the 99.9th percentile of latency, not the average. They weren't optimising for the common case — they were obsessing over the worst case. A customer in the long tail of latency is still a customer with a credit card.
The Ring
Here's the first clever trick. Traditional databases shard data by assigning ranges to specific machines. Node A gets keys 0–1000, Node B gets 1001–2000, and so on. This works until you add a third node. Then you have to reshuffle everything.
Dynamo uses consistent hashing. Imagine a circle — a hash ring — with values from 0 to 2^128 running around it. Each node gets assigned a position on the ring. When you want to store a key, you hash it, find that position on the ring, and walk clockwise until you hit a node. That node owns the key.
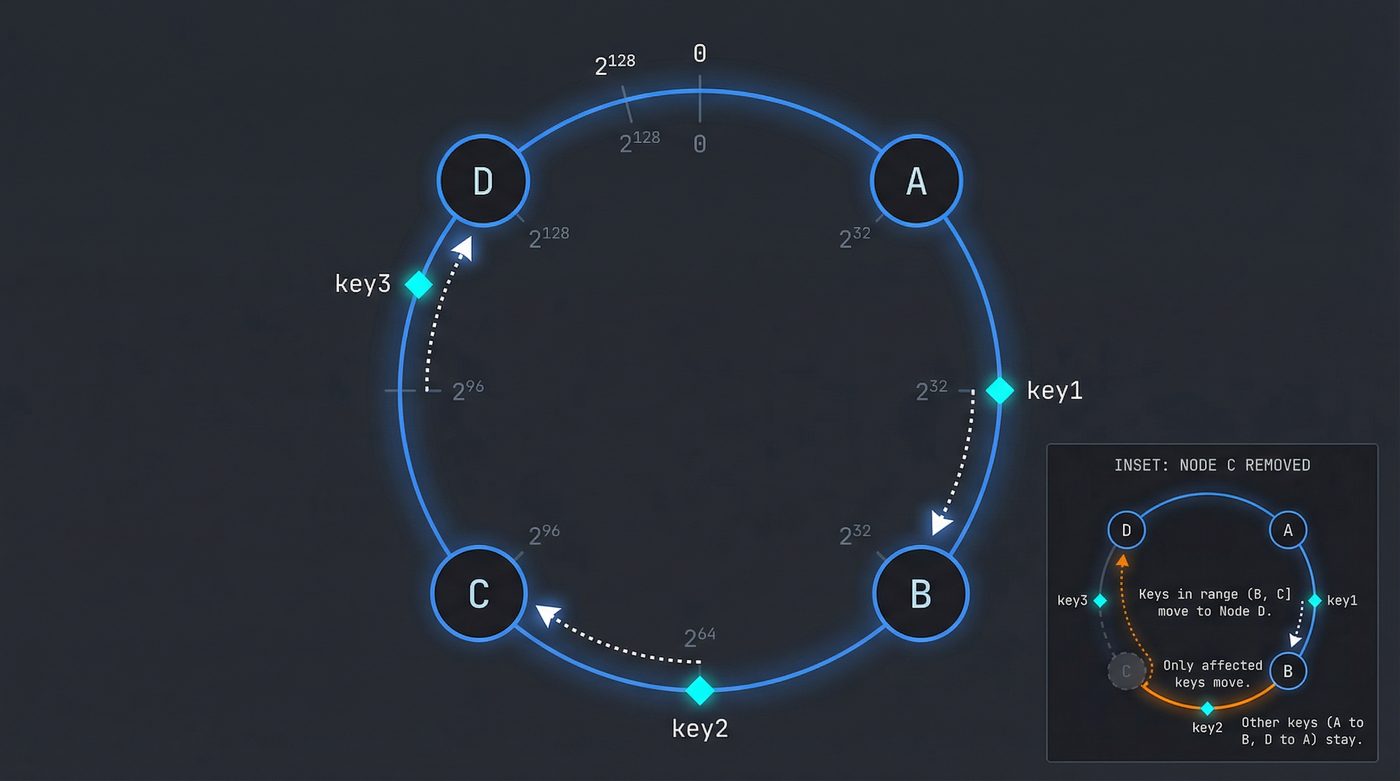
The beauty is what happens when a node dies or you add one. Only the keys between the new/dead node and its predecessor on the ring need to move. Everything else stays put. In a cluster of 100 nodes, adding node 101 moves roughly 1% of the data. Compare that to modular hashing where adding a node reshuffles almost everything.
But raw consistent hashing has a problem: nodes aren't evenly distributed. You might get unlucky and have three nodes clustered together, leaving one node responsible for half the ring.
Dynamo's fix: virtual nodes. Each physical machine gets multiple positions on the ring — say, 150 virtual nodes scattered around it. This smooths out the distribution. A beefier machine can get more virtual nodes. A machine that's struggling can shed some. The ring stays balanced without manual intervention.
I've seen teams implement consistent hashing without virtual nodes. It works fine in dev with 3 nodes. Put it in production with 20 nodes and watch the hot spots appear.
Sloppy Quorums and the Hint
In a traditional quorum system, you have N replicas, and you require W confirmations for a write and R confirmations for a read. If W + R > N, at least one node in your read set must have seen the latest write. Consistency through overlap.
Dynamo says: what if we bend this rule during failures?
Normally, a key hashes to node A, and its replicas live on nodes B and C (the next two clockwise on the ring). If node A is down, a strict quorum would refuse the write — it can't reach the primary.
Dynamo uses a sloppy quorum. If A is down, the write goes to node D instead — the next healthy node clockwise. But D knows it's not supposed to own this key. It stores the data in a separate local database along with a hint: "this data belongs to A. When A comes back, send it over."
This is hinted handoff. Node D is a temporary custodian. When A recovers, D ships the data over and deletes its local copy.
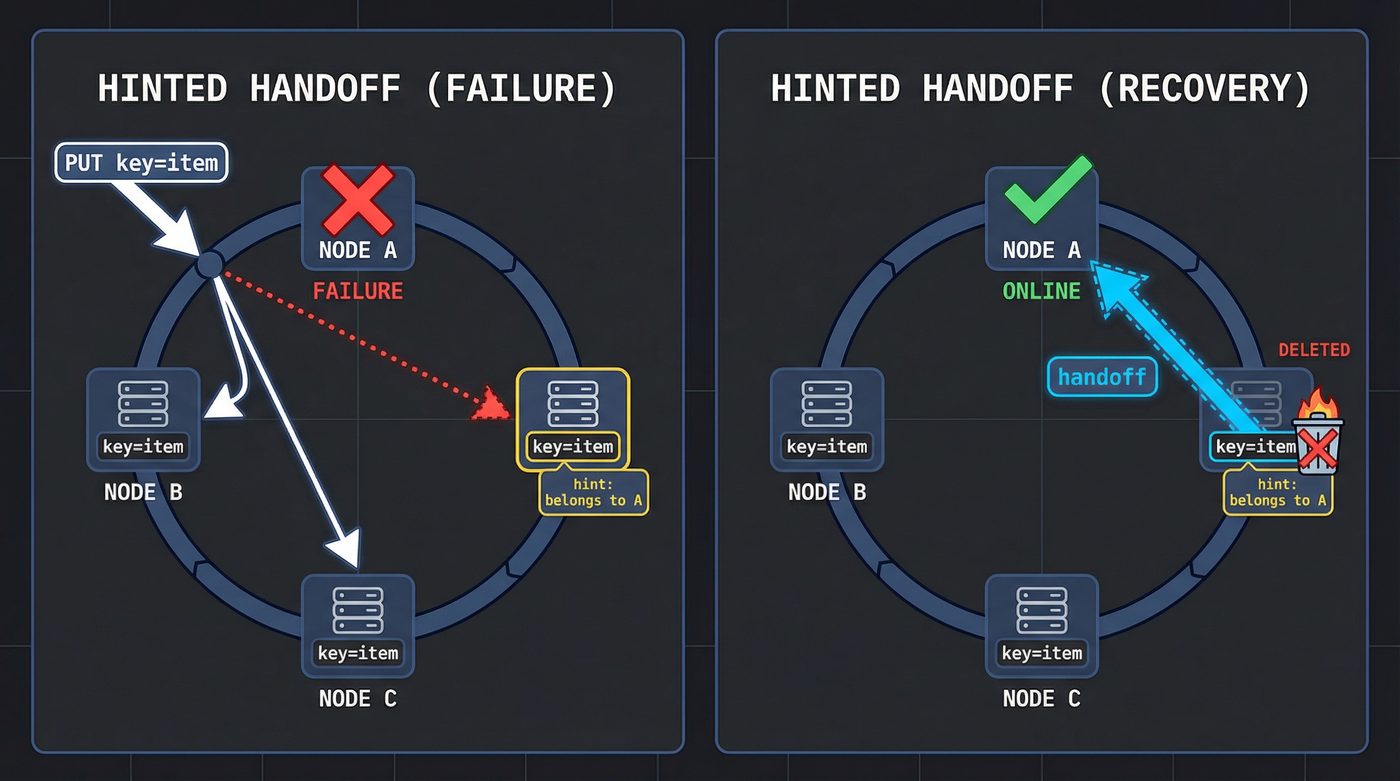
This is how "always writable" works. There's always somewhere to put the data, even if it's not the right place. The system self-heals when the partition resolves.
The trade-off is obvious: during the partition, reads might not see the latest write. If you wrote to D but read from B, you get stale data. Dynamo doesn't hide this trade-off. It puts it in your face and says "you decide how much you care."
Vector Clocks: When Two Writes Walk Into a Bar
Partitions create a specific problem. Two clients write to the same key on different sides of a partition. When the partition heals, you have two conflicting versions. Which one wins?
Dynamo's answer: neither. Both. It depends on you.
Each value in Dynamo carries a vector clock — a list of (node, counter) pairs that tracks the causal history of every write. When client 1 writes to node A, the vector clock becomes [(A, 1)]. When client 2 writes to node B without seeing client 1's write, the clock becomes [(B, 1)].
These two clocks are concurrent — neither is an ancestor of the other. Dynamo can't pick a winner. When you read the key, Dynamo returns both versions and says: you figure it out.
For a shopping cart, the merge strategy is straightforward: take the union of both carts. If one cart has items {A, B} and the other has items {A, C}, the merged cart has {A, B, C}. The customer might see an item they thought they removed — mildly confusing — but they never lose an item they added. Amazon decided that was the right trade-off.
For other use cases? Vector clock conflicts are a nightmare. I once worked on a system that used a Dynamo-style store for user profiles. When two updates happened concurrently — say, the user changed their name on their phone while their laptop synced their avatar — the application had to merge two profile objects. The merge logic was more complex than the rest of the feature combined. We should have used Postgres.
Vector clocks also have a practical problem: they grow. Every node that touches a key adds an entry. Dynamo truncates them after a threshold (based on timestamps), which can occasionally cause false conflicts. The paper acknowledges this. It's an imperfect solution to an imperfect world.
Anti-Entropy: The Background Janitor
Hinted handoff handles recent failures. But what about data that drifted apart slowly — a missed hinted handoff, a node that was down longer than the hint retention period, a subtle bit-rot?
Dynamo uses Merkle trees for anti-entropy. Each node maintains a Merkle tree over its key range. A Merkle tree is a hash tree — the leaves are hashes of individual keys, and each parent is the hash of its children, all the way up to a single root hash.
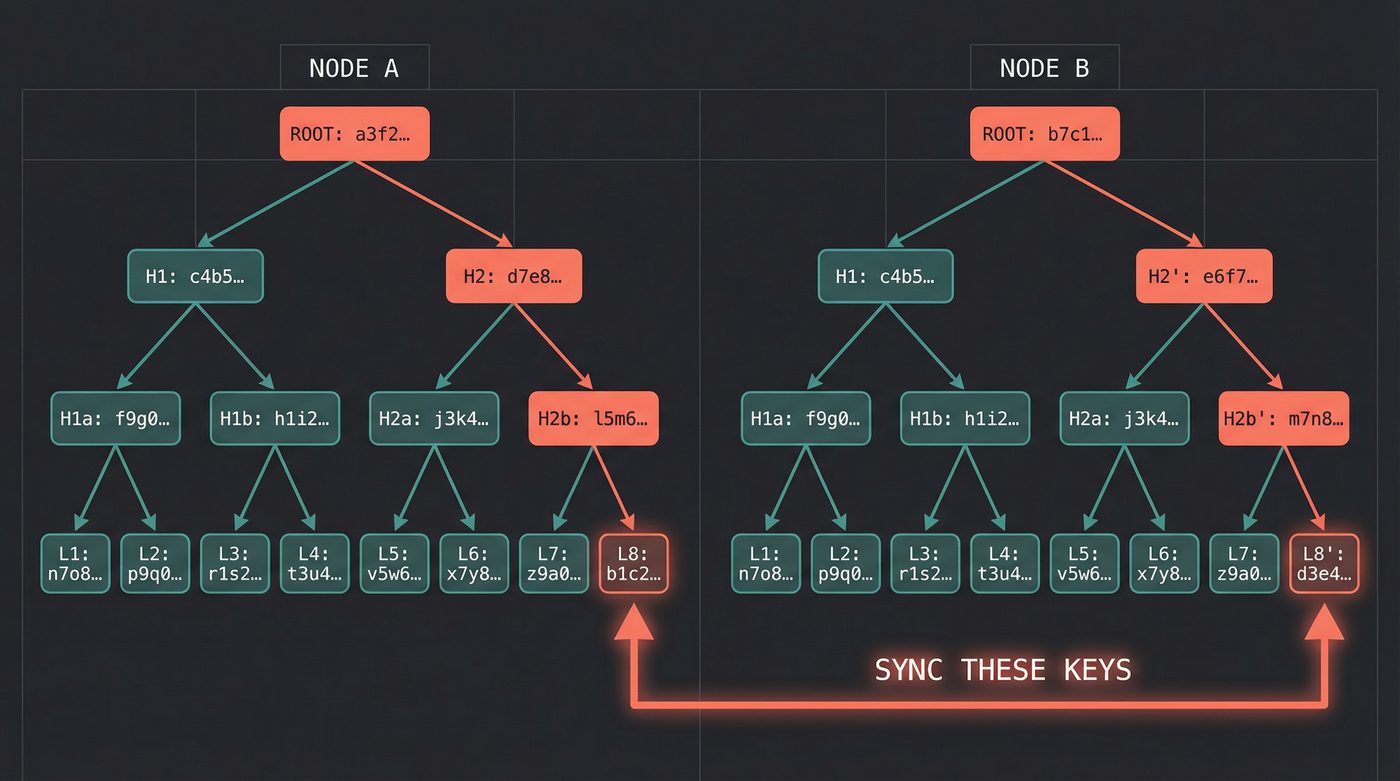
Two nodes can compare their root hashes with a single exchange. If the roots match, everything is in sync. If they don't, they recursively compare child hashes to narrow down exactly which keys diverge. Then they exchange only those keys.
This is logarithmic in the number of keys. A naive approach would compare every key — O(n). Merkle trees make it O(log n) with minimal network traffic. The same structure powers Git's integrity checking, blockchain verification, and certificate transparency logs. It turns up everywhere because it solves a fundamental problem: how do you efficiently verify that two copies of a dataset are identical?
The anti-entropy process runs continuously in the background. It's not on the critical path for reads or writes. It's the janitor that sweeps up after the system's imperfections.
Tuning the Knobs
Dynamo's quorum parameters — N, R, and W — are tunable per-table. This is where the engineering gets real.
- N = total number of replicas (typically 3)
- W = number of nodes that must acknowledge a write
- R = number of nodes that must respond to a read
The math is simple. If W + R > N, you're guaranteed to read your own writes (at least one node overlaps). Common configurations:
N=3, W=2, R=2 — balanced. You tolerate one node failure for both reads and writes. This was Dynamo's default.
N=3, W=3, R=1 — fast reads, durable writes. Every write goes everywhere. Reads only need one node. Good for read-heavy workloads where you can tolerate write latency.
N=3, W=1, R=3 — fast writes, consistent reads. Fire-and-forget writes (to one node), but read from all replicas and take the latest. This is the "always writable" configuration for the shopping cart.
N=3, W=1, R=1 — maximum speed, minimum guarantees. Both reads and writes only need one node. You might read stale data. You might lose writes if a node dies before replication. This configuration is for people who've read the paper, understood the trade-offs, and decided they genuinely don't care about some data loss. Most people who use it haven't done any of those things.
The Lineage
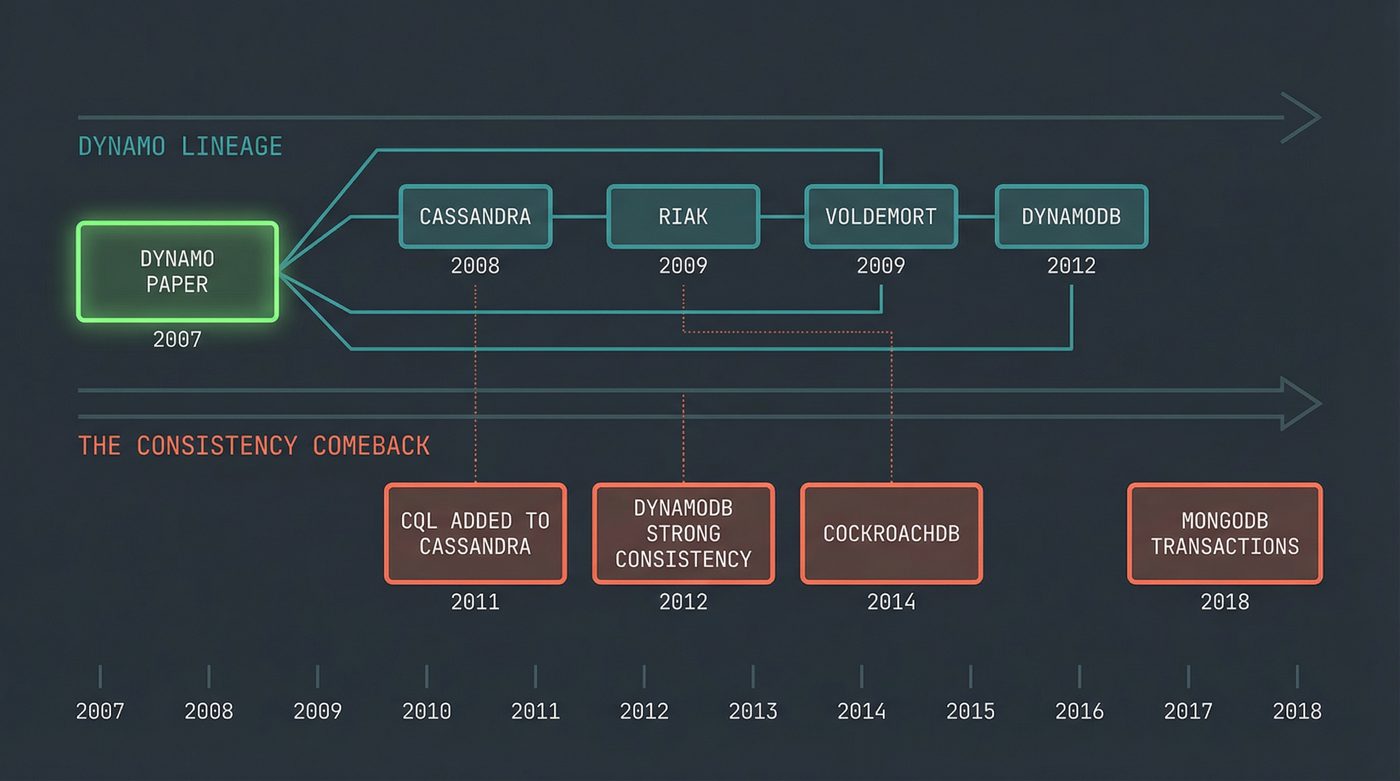
The Dynamo paper was internal to Amazon. You couldn't download Dynamo and run it. But the paper was a blueprint, and the industry photocopied it.
This is the second time we've seen this pattern in two posts. In post 32, Google published GFS and MapReduce in 2003 and 2004. They didn't open-source either system. Within a couple of years, Doug Cutting had read both papers and built HDFS and Hadoop MapReduce — open-source clones of Google's proprietary infrastructure, derived entirely from the published descriptions. The papers were the API. The implementations were everyone else's homework. Dynamo (2007) followed the same script: Amazon kept the production system in-house, but the paper was detailed enough that within two years Cassandra, Riak, and Voldemort all existed as open-source children of it. Big tech's habit of publishing the design and keeping the code is, accidentally, one of the most generative gifts the industry has ever given itself. Every "blueprint paper" launches a generation of open-source clones.
DynamoDB (2012) — Amazon's managed service. Takes the Dynamo concepts and puts them behind an API. Notably, DynamoDB's consistency model is different from the paper's Dynamo. It offers both eventually consistent and strongly consistent reads. The managed service learned from five more years of operational pain.
Cassandra (2008) — built at Facebook, open-sourced, eventually became an Apache project. Cassandra is a hybrid: it took Dynamo's distribution model (consistent hashing, tunable quorums, gossip protocol) and grafted on Bigtable's data model (column families, SSTables, log-structured merge trees). If Dynamo is the skeleton, Bigtable is the muscle. Cassandra is the Frankenstein's monster that became more popular than either parent.
Riak (2009) — Basho Technologies built what was arguably the most faithful open-source implementation of the Dynamo paper. Vector clocks, hinted handoff, Merkle trees, read-repair — all of it. Riak was beautiful distributed systems engineering. Basho went bankrupt in 2017. The market didn't want faithfulness to the paper. It wanted managed services.
Voldemort (2009) — LinkedIn's take. Used internally, open-sourced, eventually faded as LinkedIn moved to other systems. Named after the Harry Potter villain, which tells you something about how LinkedIn's engineers felt about distributed key-value stores by the time they shipped it.
The period from 2009 to 2013 was the NoSQL explosion. MongoDB, CouchDB, Redis, Neo4j, HBase — not all of them descended from Dynamo, but Dynamo created the climate. It gave the industry permission to say "maybe we don't need ACID for everything."
"NoSQL" Is a Terrible Name
The name "NoSQL" was coined at a meetup in 2009. It was a hashtag. It stuck.
It was never about SQL. SQL is a query language. You can bolt SQL onto anything — and people have. CockroachDB is a distributed, horizontally scalable database that speaks SQL. Cassandra added CQL, which looks suspiciously like SQL. Google Spanner uses SQL. The thing that Dynamo and its children rejected wasn't the query language. It was the guarantees.
What the NoSQL movement actually argued:
- Not every workload needs ACID transactions
- Horizontal scalability matters more than vertical for some use cases
- Schema flexibility is valuable during rapid iteration
- The CAP theorem means you sometimes need to choose availability over consistency
A more accurate name would have been "NoACID" or "NoConsistency" or "TradeoffsDB." But "NoSQL" fit in a hashtag, and here we are, seventeen years later, still using it.
The irony is thick. The movement that started by rejecting relational guarantees has spent the last decade adding them back. Transactions in MongoDB. Lightweight transactions in Cassandra. Strong consistency in DynamoDB. The industry discovered what the database community knew all along: most applications need consistency more than they think they do.
My Take
Dynamo was right for Amazon's shopping cart. A specific application, with specific business requirements, operated by a team that deeply understood the trade-offs.
It was wrong for most of the things developers used it for during the NoSQL hype.
I watched teams adopt Cassandra for applications that had maybe 10,000 rows. They didn't need horizontal scalability — they needed joins. They'd traded a B-tree index for a log-structured merge tree because a conference speaker told them relational databases don't scale. Their Postgres instance would have been fine on a single $20/month VPS.
The "just use Cassandra" era produced systems where a user would update their profile and then immediately see their old profile. Where two users would edit the same document and one edit would silently vanish. Where inventory counts were approximate and occasionally negative. These weren't bugs in Cassandra. They were bugs in the decision to use Cassandra.
Eventual consistency sounds harmless in a whiteboard discussion. In production, it means a user changes their email address, refreshes the page, sees the old email, panics, changes it again, and now you have three conflicting versions in your vector clock. It means your billing service reads a stale account status and charges a customer who cancelled ten seconds ago. It means your leaderboard is always slightly wrong and your most competitive users send you angry emails about it.
I'm not saying eventual consistency is bad. DNS is eventually consistent (as I covered in post 7) and the internet runs on it. But DNS updates are infrequent and the staleness window is bounded by TTLs. A shopping cart where staleness means a duplicate item is different from a bank account where staleness means a wrong balance.
The lesson from Dynamo isn't "use AP databases." It's "know your consistency requirements before you choose your database." Read post 28 on database internals. Understand what your traditional RDBMS gives you before you throw it away. The paper's authors knew exactly what they were sacrificing. Most of the developers who followed them didn't.
What Dynamo Actually Gave Us
Strip away the hype and the bad decisions made in its name. It demonstrated — rigorously, in production, at Amazon's scale — that you can build a reliable storage system from unreliable components by accepting weaker guarantees and pushing conflict resolution to the application.
Consistent hashing is now standard infrastructure. Vector clocks show up in version control systems. Merkle trees are in everything from Git to blockchains. Quorum-based replication is how distributed databases work, whether they're AP or CP. The engineering techniques outlived the hype.
And the paper itself is still one of the clearest pieces of distributed systems writing I've read. It doesn't hide behind formalism. It says "here's our business requirement, here's our design, here's what went wrong, here's what we'd do differently." That last part — the honest retrospective — is rare in academic papers. It's even rarer in industry.
The next time someone tells you to use a NoSQL database, ask them which guarantee they're willing to give up. If they can't answer, they haven't read the paper. Maybe they should start here 👆👆👆.
Further Reading
- Post 29: The Theorem That Decides Who Gets Lied To — The CAP theorem that frames Dynamo's design choice. Dynamo is the canonical AP system.
- Post 28: What Actually Happens When You Query a Database — The traditional RDBMS internals that Dynamo deliberately abandoned.
- Post 7: Your DNS is Lying to You — Another eventually consistent distributed system. DNS got the staleness trade-off right because TTLs bound it.
- Dynamo: Amazon's Highly Available Key-Value Store (2007) — The original paper. 16 pages. Read it.
- Werner Vogels — Eventually Consistent (2008) — Amazon's CTO explaining the consistency spectrum. The term itself predates this post (it appears in the Dynamo paper and earlier academic work), but Vogels' write-up is what dragged "eventually consistent" out of the literature and into industry vocabulary.
- Martin Kleppmann — Designing Data-Intensive Applications — Chapters 5-9 cover replication, partitioning, and consistency in far more depth than any blog post. The best book on this subject.
- Please stop calling databases CP or AP — Kleppmann's argument that the CAP theorem is more nuanced than the two-letter labels suggest. Required reading after the Dynamo paper.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri once spent a weekend migrating a Cassandra cluster back to Postgres and felt nothing but relief. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.