The Two Papers That Created Big Data
How Google Broke the Rules of Storage and Accidentally Built an Industry
Reading time: ~16 minutes
In 2003, a paper appeared from Google describing a file system. The authors were Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. It was 15 pages. A year later, another paper appeared — Ghemawat again, this time with Jeff Dean — describing a computation model. It was 13 pages.
Twenty-eight pages of academic writing. Between them, they launched a multi-billion-dollar industry.
Hadoop, Spark, HDFS, every "data lake" your company has, every "big data" job listing that peaked around 2014 — they all trace back to these two papers. If you've ever written a MapReduce job, queried a Hive table, or argued about whether your team actually needs a distributed file system, you've been living in the world these papers built.
The Problem Nobody Else Had Yet
To understand why these papers mattered, you need to understand the problem Google was trying to solve in the early 2000s. They were indexing the entire web. Not a sample. Not a curated collection. The whole thing.
By 2003, the web crawl was measured in petabytes. Not the kind of petabyte that a vendor puts on a slide with an asterisk — actual petabytes of data that needed to be stored, processed, and searched across thousands of machines.
The conventional approach to storing critical data at that scale was straightforward: buy expensive hardware. Enterprise storage arrays with redundant power supplies, hot-swappable drives, ECC memory, and a service contract that costs more than my first car. Sun, EMC, NetApp — these were the vendors. The philosophy was simple: prevent failure. Make the hardware so reliable that drives don't die, controllers don't crash, and data doesn't get corrupted.
Google looked at the math and said no.
Not because the hardware didn't work. It worked fine. The problem was economic. When you need to store petabytes across thousands of machines, you can't afford hardware that costs $50,000 per node. You need hardware that costs $2,000 per node. Commodity servers. Desktop-class drives. The kind of machines that fail.
And they will fail. At Google's scale, with thousands of machines, disk failures weren't an exceptional event. They were a daily occurrence. Multiple times a day. A server that runs 10,000 commodity drives will see, statistically, roughly one drive failure per day. At the scale Google was operating, the question was never "will a drive fail today" but "which ones."
The insight that changed everything: stop trying to prevent failure. Expect it. Design the system so that failure is routine and recovery is automatic.
GFS: The File System That Assumes Everything Breaks
The Google File System was designed with three assumptions that no commercial file system had ever made simultaneously:
1. Component failures are the norm, not the exception. The system is built from hundreds or thousands of commodity machines. Machines will crash. Disks will die. Memory will corrupt. Network switches will cut out. The file system must handle this without human intervention.
2. Files are huge. The typical file is hundreds of megabytes to several gigabytes. When your workload is web crawl data, log aggregation, and satellite imagery, you're not optimizing for millions of 4KB files. You're optimizing for thousands of multi-gigabyte files.
3. Writes are almost always appends. Data comes in, gets written to the end of a file, and is then read sequentially. Random writes to the middle of an existing file are so rare that GFS barely supports them. This isn't a general-purpose filesystem. It's a machine for ingesting and reading large sequential data.
The Architecture
GFS has three components: a single master, many chunk servers, and the clients.
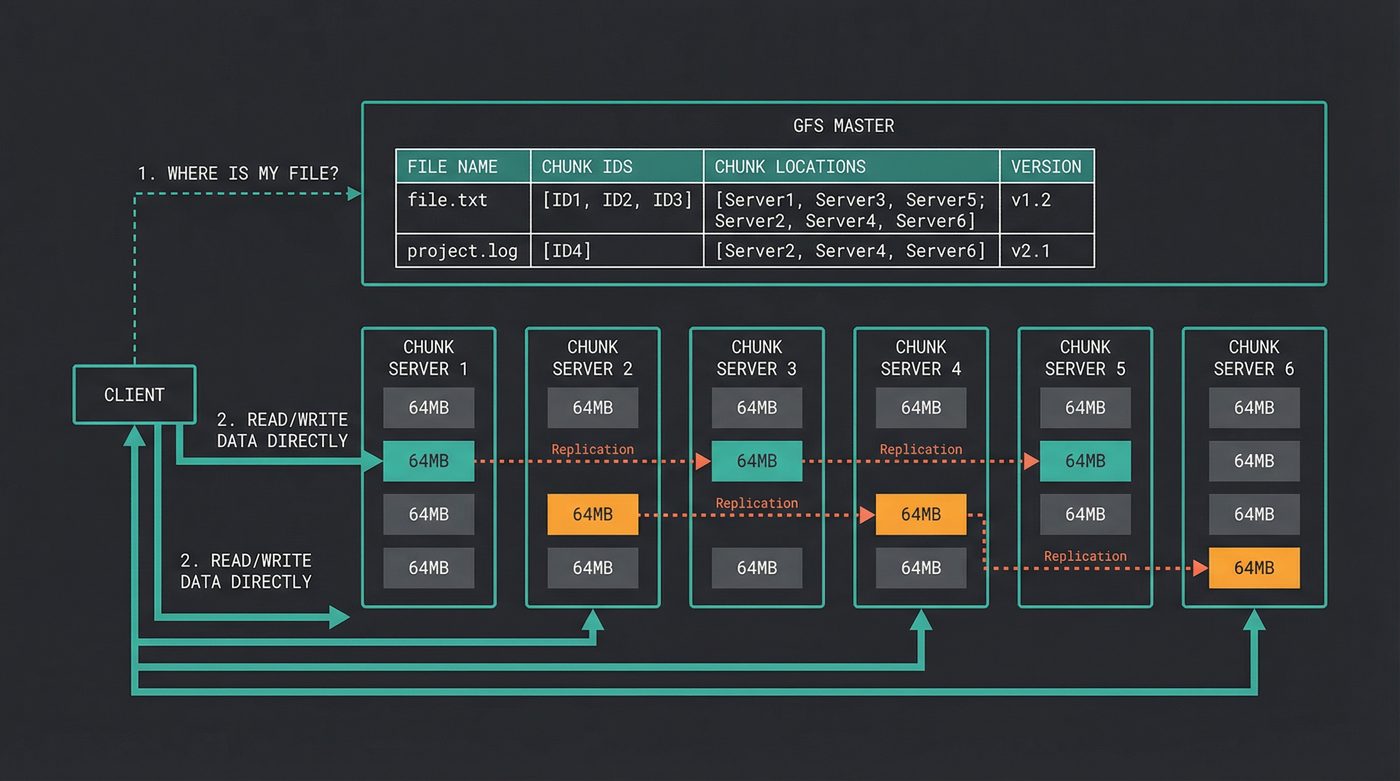
The master holds all the metadata: which files exist, which chunks they're split into, and which chunk servers hold each chunk. It does not hold any file data. The metadata is small enough to fit in RAM — a few hundred bytes per chunk — which means the master can answer "where is chunk X?" in microseconds.
The files themselves are split into chunks. Each chunk is 64 megabytes. That's enormous compared to a traditional filesystem block size of 4KB. I'll come back to why.
Each chunk is stored on a chunk server — a regular Linux box running a regular Linux filesystem (ext3, at the time). The chunk is just a file on that machine's local disk. No custom block device. No kernel module. Just files.
And here's where the design-for-failure philosophy kicks in: every chunk is replicated to three different chunk servers, on three different physical machines, ideally on three different racks. When a chunk server dies — and it will — the data is still alive on two other machines. The master notices the server is gone, picks a new chunk server, and copies the data there. The system heals itself.
The Single Master: A Deliberate Weakness
The master is a single point of failure. The GFS paper is remarkably honest about this. They considered multi-master designs and rejected them because the complexity of distributed consensus for metadata operations would slow everything down.
Instead, they kept the master simple and made it recoverable. The metadata is logged to disk and replicated to shadow masters. If the master dies, an operator can promote a shadow. It takes minutes, not hours. During that window, clients can still read from chunk servers using cached metadata — they just can't open new files or get updated chunk locations.
I love this decision because it's the kind of tradeoff that only gets made by engineers solving a real problem, not designing a theoretical system. A multi-master GFS would have been more "correct" in a distributed systems textbook. A single-master GFS is what actually got built and ran at scale. Sometimes the pragmatic choice — accepting a known weakness rather than introducing unknown complexity — is the right one.
If you've read post 29 on the CAP theorem, this is GFS choosing CP over AP: consistency and partition tolerance, at the cost of availability during master failures. (Anachronism warning: GFS predates CAP's formalisation by Gilbert and Lynch by a year, and the GFS paper itself never reaches for that vocabulary. The CP/AP framing is something I'm imposing in retrospect because it's the cleanest way to describe the choice.)
Why 64MB Chunks?
Most filesystems use block sizes between 512 bytes (2⁹) and 4 kilobytes (2¹²). GFS uses 64 megabytes (2²⁶). That's roughly 14 to 17 powers of two larger — a factor of somewhere between 16,000 and 131,000. It seems absurd until you think about the workload.
Fewer metadata entries. A 1TB file with 4KB blocks needs 262 million block pointers. With 64MB chunks, it needs 16,384. The master stores chunk metadata in RAM. The difference between tracking 262 million entries and 16,000 entries is the difference between "we need a bigger master" and "this fits comfortably."
Amortized network overhead. Every chunk operation involves a network round-trip to the master to look up chunk locations. If you're reading a 1GB file in 4KB blocks, that's 262,144 metadata lookups. With 64MB chunks, it's 16. The master stays idle. The client stays fast.
Sequential I/O patterns. Google's workloads were overwhelmingly sequential reads and appends. A MapReduce job reads a file start to finish. A crawler appends data to a log. For sequential access, large chunks mean fewer seeks and more sustained throughput.
The downside is obvious: small files waste space. A 1KB file burns 64MB of storage (times three for replication). Google knew this. They didn't care. Their workload was big files. Designing a filesystem for a workload you don't have is how you end up with something that's mediocre at everything and great at nothing.
Checksums and Self-Healing
Every chunk is divided into 64KB blocks, and every block has a 32-bit checksum. When a chunk server reads data from disk, it verifies the checksum before sending the data to the client. If the checksum fails, the server reports the corruption to the master, the client reads from a different replica, and the master schedules the corrupt chunk to be re-replicated from a healthy copy.
Disk corruption happens more often than most people think. Not "drive dead" corruption — silent corruption, where bits flip and the drive firmware doesn't notice. The classic study here is Bairavasundaram et al. (FAST '08), which tracked 1.53 million drives across NetApp production storage for 41 months and found that 0.86% of enterprise (SCSI/FC) drives and 0.466% of nearline (SATA) drives developed at least one silent checksum mismatch in that window — with nearline drives an order of magnitude worse than enterprise. At Google's scale, where you have hundreds of thousands of commodity SATA drives, that translates to silent corruption events every day. The checksums catch them. The replication fixes them. No human needed.
This is the core philosophy: the system doesn't prevent failures. It detects them and heals from them, continuously, automatically.
MapReduce: Write Two Functions, Run on a Thousand Machines
A year after GFS, Dean and Ghemawat published the MapReduce paper. If GFS solved "how do you store petabytes," MapReduce solved "how do you process petabytes."
The idea is borrowed from functional programming — Lisp's map and reduce functions, which had been around since the 1950s. Dean and Ghemawat didn't invent the concept. They made it work across a thousand machines.
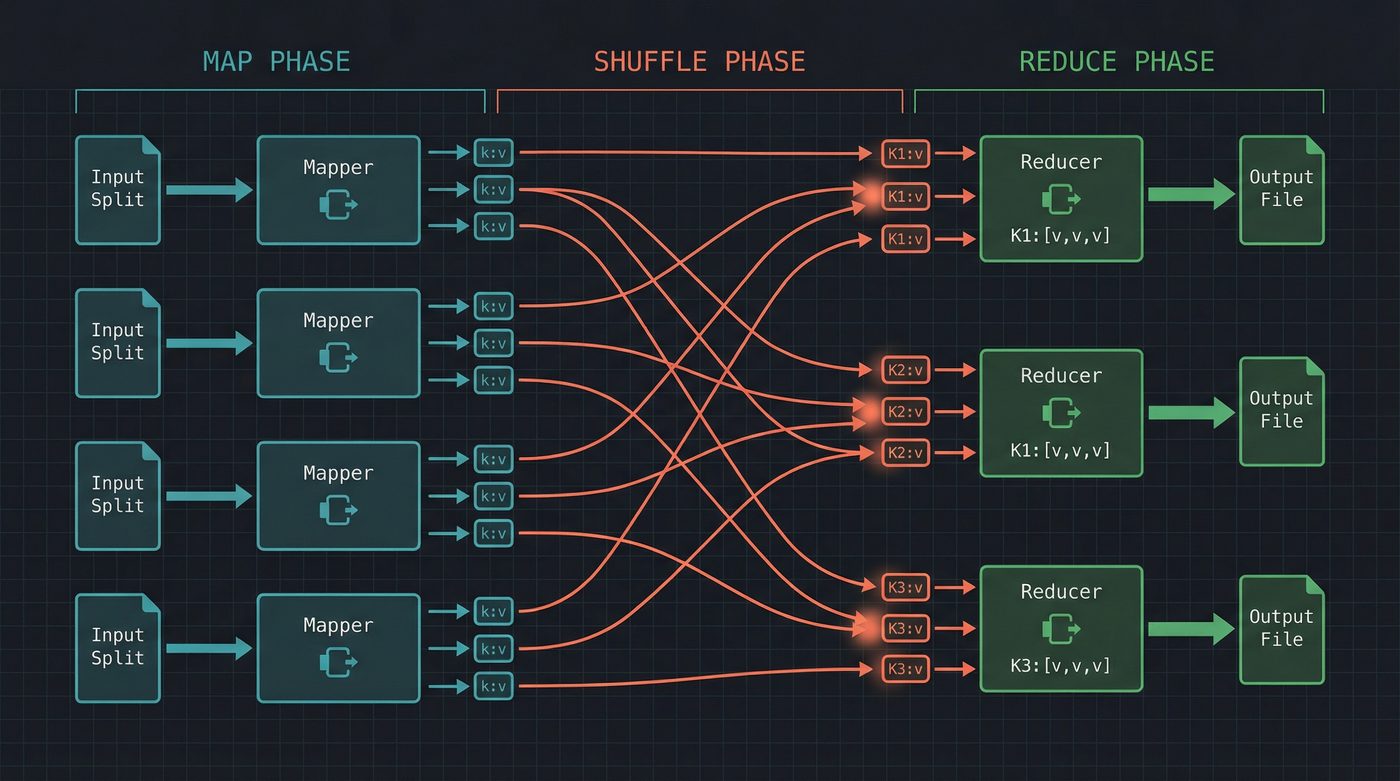
The Three Phases
Map. You write a function that takes a record and emits zero or more key-value pairs. The framework calls your function on every record in the input, in parallel across hundreds of machines. You don't think about distribution. You don't think about which machine gets which record. You write logic for one record.
Shuffle. The framework takes all the key-value pairs emitted by every mapper and groups them by key. This is the network-intensive phase — data moves between machines so that all values for a given key end up on the same node. You don't write any code for this. The framework does it.
Reduce. You write a function that takes a key and all its values, and produces an output. Again, you write logic for one key. The framework calls your reducer for every unique key, in parallel.
That's it. Every complex distributed computation decomposed into three phases. Word count, inverted index construction, log aggregation, machine learning data preprocessing — all of it expressible as map and reduce.
A Concrete Example
Word count — the "hello world" of MapReduce:
# Map: emit (word, 1) for each word in the line
def mapper(line_number, line_text):
for word in line_text.split():
emit(word.lower(), 1)
# Reduce: sum all counts for each word
def reducer(word, counts):
emit(word, sum(counts))
// The actual Hadoop API — verbose, but this is what people wrote for years
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
public void map(Object key, Text value, Context context) {
for (String word : value.toString().split("\\s+")) {
context.write(new Text(word.toLowerCase()), new IntWritable(1));
}
}
}
You write those two functions. The framework distributes the input across 1,000 machines, runs your mapper on each split, shuffles the intermediate data, runs your reducer on each key, and writes the output. It handles machine failures mid-job — if a mapper dies, it reruns the map task on another machine. If a reducer dies, it restarts the reduce task. You don't write retry logic. You don't write network code. You write business logic for a single record.
That was revolutionary.
Before MapReduce, distributed computation meant writing your own socket handling, your own task scheduling, your own failure detection, your own data partitioning. Every team reinvented these wheels, poorly. MapReduce said: those are framework problems, not application problems. And it was right.
Data Locality: The Secret Weapon
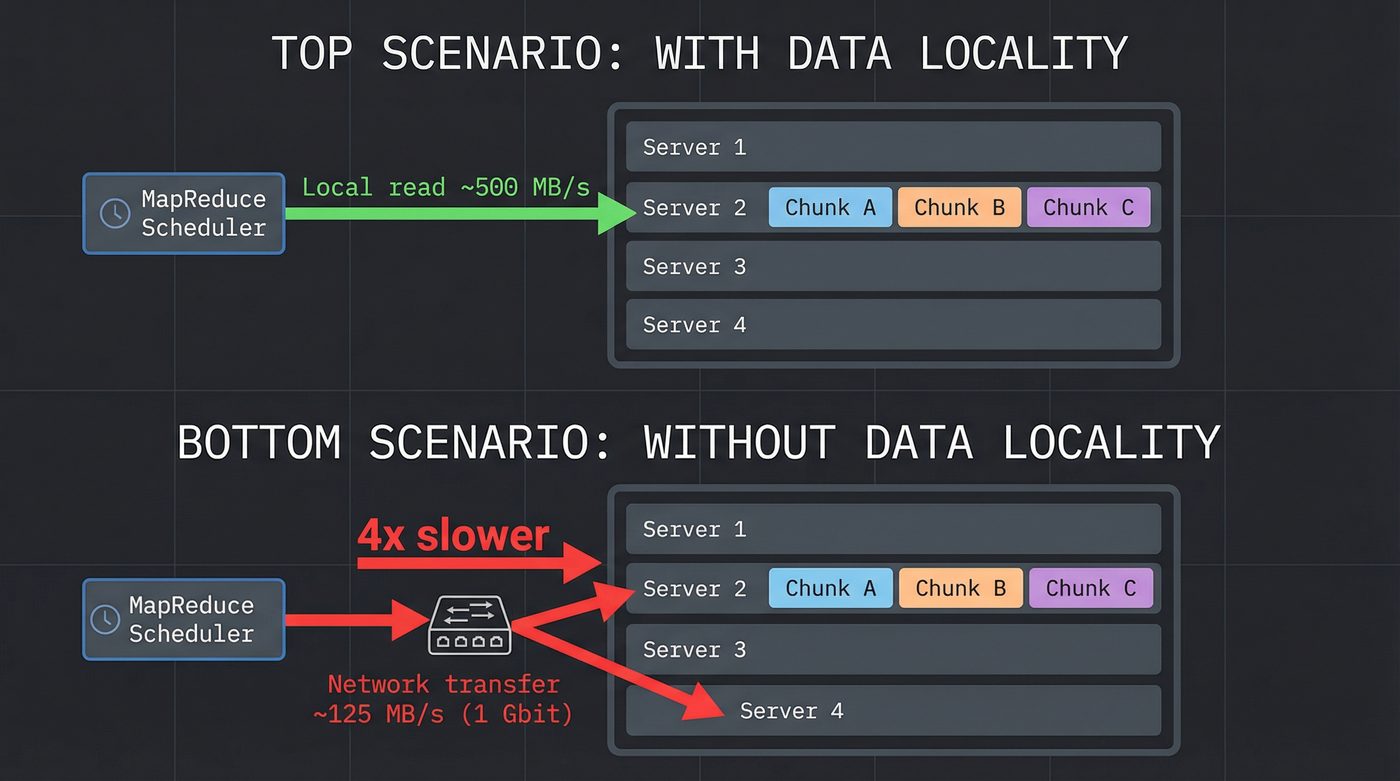
Here's the detail that separated MapReduce from "just run the same code on a lot of machines." MapReduce was integrated with GFS. The scheduler knew where the data lived — which chunk servers held which chunks. When it assigned a map task, it tried to run the mapper on a machine that already had the data locally.
Moving computation to the data instead of moving data to the computation. At petabyte scale, this is the difference between "job finishes in an hour" and "the network melts."
The Lineage: From Papers to Products
Google published these papers but not the code. The papers were detailed enough that a determined engineer could build a clone. A determined engineer did.
Doug Cutting was working on an open-source search engine called Nutch, which he'd started in 2002 with Mike Cafarella. He read the GFS and MapReduce papers and thought: I need this. Between 2004 and 2006, he and Cafarella built open-source implementations of both systems on top of Nutch. The file system became HDFS — the Hadoop Distributed File System. The computation framework became Hadoop MapReduce. The umbrella project was named Hadoop, after Cutting's son's toy elephant. Yahoo hired Cutting in January 2006, after Hadoop was already underway, and committed serious engineering resources to it from there — but the work didn't start at Yahoo, it landed there.
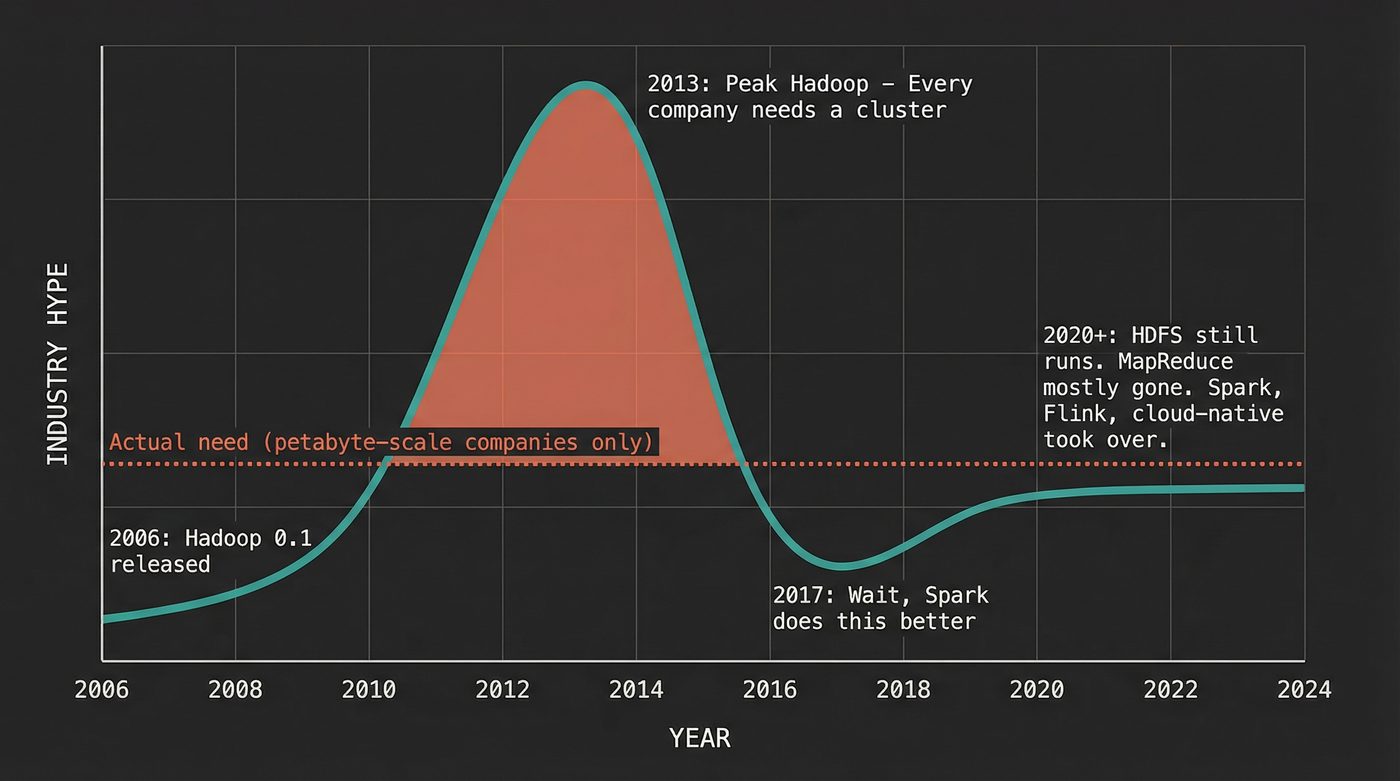
By 2008, Hadoop was running in production at Yahoo. That summer, Owen O'Malley's team used a 910-node Hadoop cluster to sort a terabyte of data in 209 seconds, winning that year's Daytona GraySort benchmark — the first time an open-source, general-purpose system took the title. The era of open-source big data had begun.
Then the Hadoop ecosystem exploded. Hive (SQL on MapReduce, from Facebook). Pig (dataflow scripting, from Yahoo). HBase (wide-column store, inspired by Google's Bigtable). ZooKeeper (distributed coordination). Oozie (workflow scheduling). Every company that touched large data started building on Hadoop. Conferences materialized. Startups raised hundreds of millions. Cloudera, Hortonworks, MapR — all billion-dollar bets on the Hadoop stack.
Spark: The Fix for MapReduce's Biggest Flaw
MapReduce had a problem. Between every map-reduce step, it wrote all intermediate data to disk. If your computation needed multiple passes over the data — and many do — you were reading and writing the full dataset to HDFS multiple times.
For a single-pass word count, this is fine. For iterative algorithms like machine learning (gradient descent needs dozens of passes over the data) or graph processing (PageRank iterates until convergence), it was brutal. Each iteration meant a full disk write and a full disk read. At petabyte scale, that's hours of I/O that accomplishes nothing.
In 2010, Matei Zaharia at UC Berkeley published the Spark paper. The core idea: keep intermediate data in memory between operations. He introduced Resilient Distributed Datasets (RDDs) — immutable, partitioned collections that live in RAM across the cluster, with a lineage graph that tracks how each partition was derived so it can be recomputed if a machine fails.
Spark was 10 to 100 times faster than MapReduce for iterative workloads. Not because the algorithms were better. Because the data stayed in memory instead of bouncing to disk between steps. The insight was almost embarrassingly obvious in retrospect: stop doing unnecessary I/O.
I remember the first time I ran a Spark job that replaced a MapReduce pipeline. The MapReduce version took 45 minutes. The Spark version took 3. Same data, same logic, same cluster. The difference was entirely I/O elimination. I stared at the console for a minute, convinced something had gone wrong. It hadn't. The data had stayed in RAM.
The Honest Take: Most Companies Didn't Need This
Here's where I lose some people.
Between 2010 and 2016, the Hadoop hype cycle was extraordinary. Every company with more than a few terabytes of data was told they needed a Hadoop cluster. Vendors were happy to sell them one. Consultants were happy to set it up. Engineers were happy to put "Hadoop" on their resumes.
The problem: most of these companies had gigabytes, not petabytes. They had data that fit comfortably in the RAM of a single modern server. They bought a 20-node cluster to process datasets that a PostgreSQL instance with a good index could handle in seconds.
I watched a team spend six months building a Hadoop pipeline to process 50GB of daily log data. Fifty gigabytes. That's the size of a large laptop's swap file. You could process it with awk and sort on a single machine in under a minute. But "awk pipeline" doesn't look as good on a performance review as "distributed data processing framework."
The MapReduce abstraction is powerful, but it has overhead. Spinning up a Hadoop job has fixed costs: JVM startup, task scheduling, shuffle phase network negotiation. For small datasets, that overhead dominates. A MapReduce word count on 1GB of text takes longer than wc -w on the same file, because the framework setup costs more than the actual computation.
The data industry had a classic case of solving for the wrong constraint. Google needed MapReduce because they had petabytes of data and thousands of machines. Most companies needed MapReduce because... their VP of Engineering saw a conference talk.
But — and this matters — for the companies that genuinely needed it, Hadoop changed everything. Facebook, Yahoo, LinkedIn, Twitter, Netflix — companies with genuine petabyte-scale problems. For them, the alternative to Hadoop was building their own distributed storage and computation from scratch. Hadoop gave them something that worked, was open source, and had a growing community. The value was real. The hype was also real. Both things can be true.
HDFS Today: Twenty Years and Still Standing
HDFS is still here. Not as the shiny new thing — as infrastructure. The kind of infrastructure that runs so reliably that people forget it exists.
The single-NameNode problem (GFS's single-master weakness, inherited by HDFS) got solved. NameNode HA, introduced in Hadoop 2.0, runs two NameNodes in active-standby configuration using a shared edit log via a quorum journal. When the active NameNode dies, the standby takes over in seconds. No manual intervention. The weakness that the original GFS paper honestly acknowledged became an engineering problem that was honestly solved.
Federation, also in Hadoop 2.0, addressed the other scaling limit: a single NameNode managing the metadata for the entire cluster. With federation, different directories can be managed by different NameNodes, each with their own namespace. The cluster scales horizontally for metadata, not just data.
It's 20 years old and it works. Not glamorous. Not trendy. But the number of enterprises still running HDFS as the backbone of their data infrastructure is staggering. I know organizations running clusters that were first deployed in 2012 and have been in continuous operation since. Drives have been replaced. Nodes have been swapped. Software has been upgraded. But the data has been there the whole time, checksummed, replicated, and self-healing.
The original GFS paper described a system designed to survive hardware failures automatically. HDFS does that. Every day. For thousands of organizations. Across millions of machines. The design-for-failure philosophy turned out to be exactly right.
What These Papers Actually Taught Us
The technical details matter — chunk sizes, replication factors, map-shuffle-reduce. But the lasting contribution of these two papers isn't the specifics. It's three ideas that changed how an entire industry thinks about data:
Design for failure. Don't buy expensive hardware to prevent failures. Buy cheap hardware and build software that survives them. This idea now runs everything from HDFS to S3 to Kubernetes.
Separate metadata from data. The master knows where things are. The chunk servers know what things are. Metadata is small, fits in RAM, and can be replicated cheaply. Data is large, stays on disk, and replication is the fault-tolerance mechanism. This separation appears in every distributed system built since.
Declarative distributed computation. Don't tell the framework how to distribute work. Tell it what you want computed. Map and reduce are declarations of intent. The framework handles the messy details of scheduling, retries, data locality, and fault tolerance. Every data framework since — Spark, Flink, Beam, Dask — follows this principle.
If you've read post 04 on reading a file, you saw the stack of machinery involved in reading bytes from a single drive on a single machine. GFS took that entire stack and made it work across thousands of machines, with the additional complication that any machine could die at any moment. If you've read post 15 on RAM, you know why Spark's "keep it in memory" approach was such a dramatic improvement over MapReduce's "write everything to disk" — the latency difference between RAM and disk is five orders of magnitude.
Twenty-eight pages. Two papers. An industry.
Further Reading
- Post 04: What Actually Happens When You Read a File — The single-machine I/O stack that GFS distributes across thousands of nodes.
- Post 15: What Your Code Does When It Says "Memory" — Why keeping data in RAM (Spark's insight) is five orders of magnitude faster than disk.
- Post 29: The CAP Theorem — GFS chose CP. Here's what that means and why.
- The Google File System (2003) — Ghemawat, Gobioff, Leung. The original paper. 15 pages that changed storage.
- MapReduce: Simplified Data Processing on Large Clusters (2004) — Dean, Ghemawat. The computation model that launched Hadoop.
- HDFS Architecture Guide — The open-source implementation of GFS's ideas. Still maintained. Still running.
- Spark: Cluster Computing with Working Sets (2010) — Zaharia et al., HotCloud '10. The original Spark paper that introduced RDDs and the case for keeping intermediate data in memory between stages.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri has mass-replicated more config files to the wrong HDFS directory than he'd like to admit. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.