The Protocol That Keeps Reinventing Itself
HTTP/1.1, HTTP/2, and HTTP/3: Three Answers to the Same Question
Reading time: ~15 minutes
You open a webpage. Forty-seven resources load -- HTML, CSS, JavaScript, images, fonts, API calls. In HTTP/1.1, your browser opened six TCP connections and prayed. In HTTP/2, it opened one and multiplexed everything. In HTTP/3, it ditched TCP entirely and built on UDP.
Three versions of the same protocol. Three radically different transport strategies. The same question underneath all of them: how do you move a webpage across the internet without the user noticing?
Those who know me are a little worried right now. Have no fear — I'll stay in my lane. Just the protocol, no UX. 😉
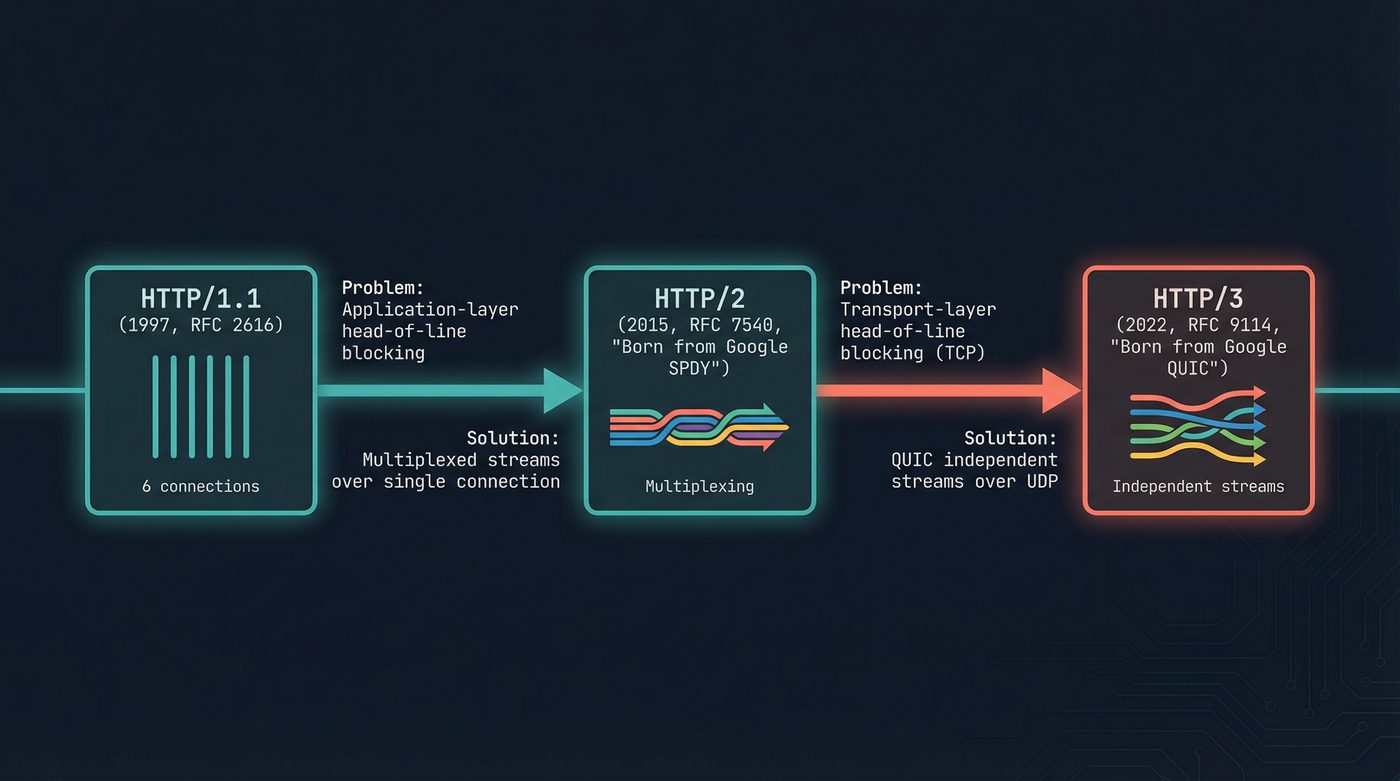
HTTP/1.1: The Era of Workarounds
A quick detour to what came before. HTTP/1.0 (RFC 1945, 1996) was the version that nearly killed the web before it started. One request per TCP connection. Want an image? New connection. Want a second image? New connection. On a page with 47 resources, that's 47 TCP three-way handshakes. The protocol also had no way to host multiple sites on one IP address — the request said GET /index.html without specifying which site, so every domain needed its own server IP.
HTTP/1.1 fixed both. The definitive spec is RFC 2616 from June 1999 (RFC 2068 came first in 1997, but 2616 is the one everyone remembers). Two changes mattered more than anything else: persistent connections — Connection: keep-alive became the default, so one TCP connection could carry many requests — and the Host: header, which forced the browser to tell the server which domain it was asking about. That one header is the reason a single server IP can host thousands of websites. It's the reason shared hosting exists. It's the reason the modern web scales economically.
Every HTTPS request your browser has made today started with a Host: header. Thank HTTP/1.1.
HTTP/1.1 is a text protocol. Your browser sends a plain-text request, the server sends a plain-text response, and the connection sits idle until the next request. One request, one response, one at a time.
The protocol technically supports pipelining -- sending multiple requests without waiting for responses. Nobody uses it. The responses have to come back in order, which means if the first response is slow, everything behind it waits. That's head-of-line blocking, and it killed pipelining in practice. Most browsers never even enabled it.
The workaround? Open more connections. Browsers settled on six TCP connections per domain. Six parallel slots for requests. It helped, but six connections means six TCP handshakes, six TLS negotiations (post 20), six congestion windows warming up independently. On a high-latency connection, that setup cost alone could take a second.
And developers invented their own hacks on top of that.
Domain sharding. If the browser limits you to six connections per domain, split your assets across cdn1.example.com, cdn2.example.com, cdn3.example.com. Twelve connections per domain? No -- eighteen connections total, with eighteen DNS lookups (post 07) and eighteen TLS handshakes. It worked. It was grotesque.
Sprite sheets. Combine fifty icons into one big image and use CSS to show the right rectangle. One HTTP request instead of fifty. A perfectly reasonable response to a protocol that makes requests expensive. I don't miss it.
CSS and JavaScript inlining. Shove your styles and scripts directly into the HTML. Kills cacheability, bloats every page load, but saves you two round trips. The kind of trade-off you make when the protocol is fighting you.
Concatenation. Bundle all your JavaScript into one massive file. All your CSS into one massive file. The build tools from that era -- Grunt, Gulp, the early Webpack configs -- half their complexity existed to work around HTTP/1.1.
Every one of these was a reasonable hack. And every one of them is an anti-pattern under HTTP/2. The protocol's limitations shaped an entire generation of web performance tooling that we're still unwinding.
Headers were another problem. HTTP/1.1 headers are plain text, sent with every request, uncompressed. A typical request carries 700 bytes to 2 KB of headers -- cookies, user-agent strings, accept headers, authentication tokens. On a page with forty resources, that's 28-80 KB of redundant header data. The same cookies, the same user-agent, forty times.
HTTP/2: One Connection to Rule Them All
HTTP/2 shipped in 2015 (RFC 7540), born from Google's SPDY experiment. The pitch: stop opening six connections. Open one. Multiplex everything over it.
The Binary Framing Layer
HTTP/1.1 is text. HTTP/2 is binary. Instead of parsing GET /index.html HTTP/1.1\r\n as a string, HTTP/2 breaks every message into frames -- small binary chunks with a type, a length, a stream ID, and flags. A HEADERS frame carries the request metadata. DATA frames carry the body. The binary format is faster to parse, more compact, and -- critically -- allows interleaving.
You lose the ability to telnet to a server and type a request by hand. I mourned this for about thirty seconds.
Streams and Multiplexing
Every request/response pair in HTTP/2 gets a stream -- a logical channel identified by an integer. Multiple streams share a single TCP connection. Frames from different streams can interleave on the wire. Your CSS, your JavaScript, your API response, and three images can all be in flight simultaneously over one connection.
Single TCP connection
┌─────────────────────────────────────────────┐
│ Stream 1: GET /index.html │
│ Stream 3: GET /style.css │
│ Stream 5: GET /app.js │
│ Stream 7: GET /hero.jpg │
│ Stream 9: GET /api/user │
│ │
│ Frames interleaved: │
│ [H:1][H:3][H:5][D:1][D:3][H:7][D:5][D:7] │
└─────────────────────────────────────────────┘
H = HEADERS frame, D = DATA frame
Numbers = stream IDs
One TCP handshake. One TLS negotiation. One congestion window. All the overhead that HTTP/1.1 paid six times, HTTP/2 pays once. Domain sharding is now actively harmful -- it prevents multiplexing.

HPACK: Compressing the Repetition Away
HTTP/2 introduced HPACK (RFC 7541) for header compression. Both sides maintain a shared table of previously sent headers. If you sent cookie: session=abc123 on request one, request two can reference it by index -- a single byte instead of thirty. Common headers like :method: GET and :scheme: https have pre-assigned indices. Huffman encoding compresses the rest.
That 80 KB of redundant headers? A few hundred bytes after HPACK. I'm not going to spend more time on this because the mechanism, while clever, isn't the interesting part of this post.
Server Push (RIP, we barely knew thee)
HTTP/2 lets the server send resources the client hasn't asked for yet. The server knows you'll need style.css when you request index.html, so it pushes it proactively.
Everyone was excited about this in 2015. Almost nobody uses it in 2026. Chrome removed support in 2022. The problem: the server doesn't know what's already in the browser's cache. Push a 200 KB stylesheet the browser already has cached and you've wasted bandwidth. Combine that with the complexity of configuring push correctly, and the feature died on the vine. The 103 Early Hints response code -- which tells the browser to preload resources without pushing them -- turned out to be the better idea.
Server push is the HTTP/2 feature that taught me that "technically superior" and "practically useful" are different things. How well I learnt the lesson is a different question.
The Problem HTTP/2 Couldn't Solve
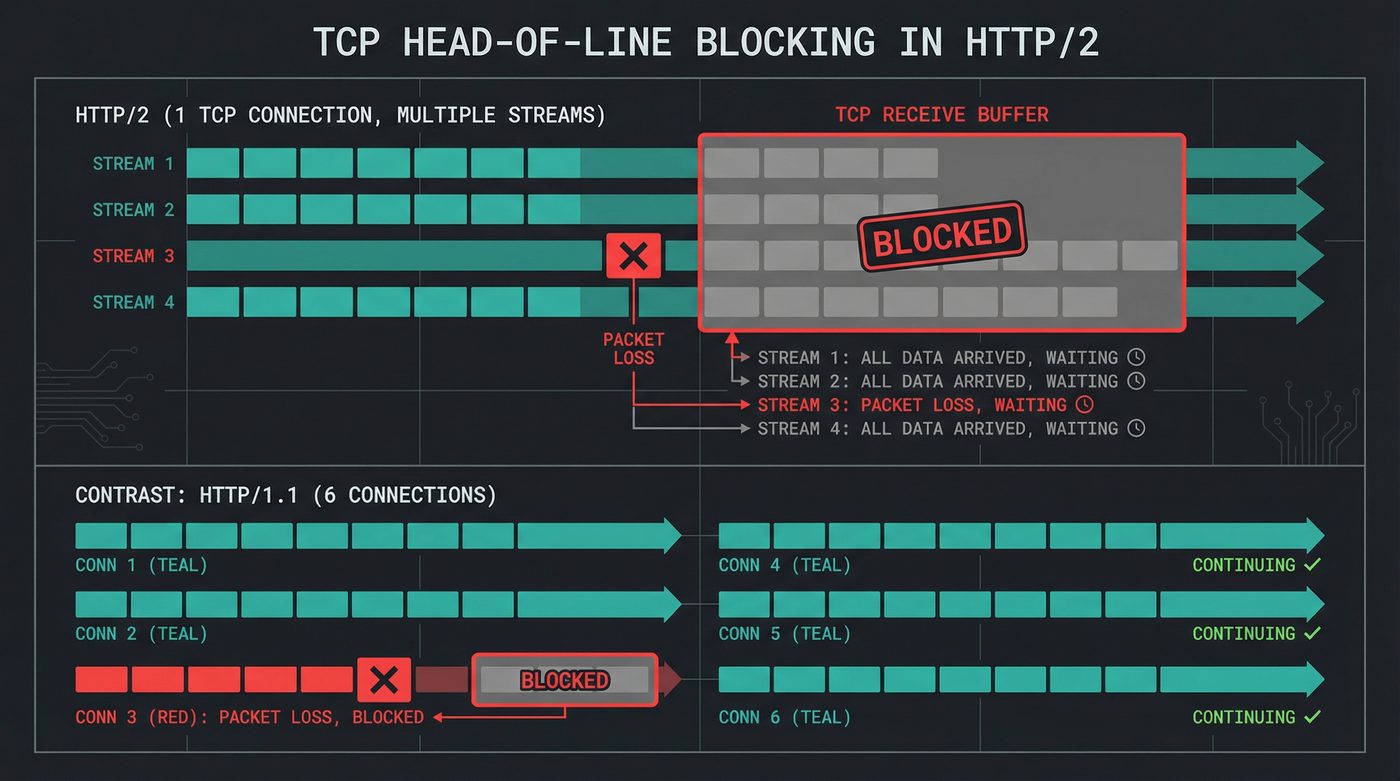
HTTP/2 solves head-of-line blocking at the application layer. Streams are independent. The HTTP layer can process stream 3's response while stream 1 is still loading.
But underneath, it's still TCP (post 08). And TCP is an ordered byte stream. TCP guarantees that bytes arrive in the exact order they were sent. If packet 47 is lost, the kernel holds packets 48 through 200 in a buffer and waits for the retransmission of 47 before delivering any of them to the application.
That means a single lost packet on the wire blocks all HTTP/2 streams. Stream 7 is done. Stream 9 is done. They're sitting in the kernel's receive buffer, complete and usable, but TCP won't release them until stream 1's missing packet arrives.
HTTP/2 didn't eliminate head-of-line blocking. It moved it from the application layer to the transport layer. On a clean, low-loss network -- a wired datacenter connection, a good home fibre line -- you never notice. On a cellular connection dropping 2% of packets, it's measurable. On a bad WiFi link, HTTP/2 can perform worse than HTTP/1.1 with six connections, because those six connections meant one lost packet only blocked one-sixth of your requests.
HTTP/3: The Nuclear Option
You can't fix TCP's head-of-line blocking from above. TCP's byte ordering is baked into the kernel. You can't tell TCP "deliver these bytes out of order, I'll sort them out." The API doesn't exist. The kernel won't do it. Even if you wrote your own TCP stack in userspace, middleboxes -- firewalls, NATs, load balancers -- expect TCP to behave like TCP. They inspect sequence numbers, track connection state, and drop packets that don't play by TCP's rules.
The only way to fix transport-layer head-of-line blocking is to use a different transport.
QUIC: Not "Just UDP"
QUIC runs on top of UDP. Full stop. But I need to be emphatic about what QUIC is not: it is not "HTTP over raw UDP." That would be insane. UDP provides no reliability, no ordering, no flow control, no congestion control. If you lobbed HTTP requests into raw UDP datagrams, half of them would vanish into the void.
QUIC reimplements almost everything TCP does -- reliable delivery, retransmission, congestion control, flow control -- from scratch, in userspace, on top of UDP's unreliable datagrams. It uses UDP as a dumb pipe to get packets past middleboxes that would drop anything that isn't TCP or UDP.
But QUIC reimplements these features differently than TCP. And the differences are the whole point.
Independent Streams: THE Reason HTTP/3 Exists
In QUIC, streams are a first-class transport concept. Each stream has its own sequence numbers, its own ordering, its own delivery guarantees. If a packet carrying data for stream 3 is lost, QUIC retransmits it. Streams 1, 2, and 4 keep flowing. Their data arrives, gets delivered to the application, and life goes on.
This is it. This is the reason Google spent years building QUIC and then pushed it through the IETF as a standard. Everything else -- the faster handshake, the connection migration, the baked-in encryption -- those are nice. Independent streams is the structural change.
QUIC connection
┌────────────────────────────────────────────────┐
│ Stream 1: ████████████████████ ✓ delivered │
│ Stream 2: ████████████████████ ✓ delivered │
│ Stream 3: ████████░░░░████████ ⟳ retransmit │
│ Stream 4: ████████████████████ ✓ delivered │
│ │
│ Lost packet only affects Stream 3 │
│ Streams 1, 2, 4 delivered immediately │
└────────────────────────────────────────────────┘
On a clean network, this doesn't matter much. Packet loss is rare and retransmissions are fast. On a mobile network dropping 1-3% of packets -- which is a normal Tuesday for anyone on a crowded cell tower -- independent streams are the difference between a smooth page load and a stutter that blocks everything for 100 milliseconds while TCP retransmits.
0-RTT: The Handshake Collapses
TCP needs a three-way handshake before data flows. Then TLS adds its own handshake -- one round trip for TLS 1.3, two for TLS 1.2. A cold connection to an HTTPS server costs two round trips before a single byte of your request is sent.
QUIC merges them. TLS 1.3 isn't layered on top of QUIC -- it's built into QUIC. The transport handshake and the cryptographic handshake happen simultaneously. One round trip, and you're sending encrypted data.
For reconnections, it gets better. If you've connected to this server before, QUIC supports 0-RTT resumption -- your first packet carries encrypted application data. The server can begin processing your request before the handshake even completes. There are replay attack considerations with 0-RTT (you shouldn't use it for non-idempotent requests), but for a GET / it's safe and it's fast.
HTTP/1.1 + TLS 1.2 HTTP/2 + TLS 1.3 HTTP/3 (QUIC)
┌───────────────┐ ┌──────────────┐ ┌──────────────┐
│ TCP SYN │ 1 RTT │ TCP SYN │ 1 RTT │ QUIC Initial │ 1 RTT
│ TCP SYN-ACK │ │ TCP SYN-ACK │ │ + TLS hello │
│ TCP ACK │ │ TCP ACK │ │ │
├───────────────┤ ├──────────────┤ │ │
│ TLS Hello │ 2 RTTs │ TLS Hello │ 1 RTT │ (combined) │
│ TLS Finished │ │ TLS Finished │ ├──────────────┤
├───────────────┤ ├──────────────┤ │ DATA │
│ HTTP Request │ │ HTTP Request │ └──────────────┘
└───────────────┘ └──────────────┘
Total: 3 RTTs Total: 2 RTTs Total: 1 RTT
(0 RTT on resumption)
On a transatlantic connection with 80ms round-trip time, that's 240ms versus 160ms versus 80ms before the first byte of your request. On a satellite link at 600ms RTT, it's 1.8 seconds versus 1.2 seconds versus 600ms. The math compounds.
Connection Migration: Your Phone Switches Networks
TCP connections are identified by a four-tuple: source IP, source port, destination IP, destination port (post 08). Change any one of those and the connection is dead. Walk from WiFi to cellular, your IP changes, every TCP connection drops. Your browser reconnects, renegotiates TLS, and replays any in-flight requests. You see a brief stutter.
QUIC connections use a connection ID -- a random identifier that both sides agree on during the handshake. The connection ID doesn't change when your IP changes. Your phone switches from WiFi to LTE, the packets start arriving from a different IP address, the server matches them to the existing connection by ID, and nothing is interrupted.
I've tested this by walking between WiFi access points while streaming a video over QUIC. The video doesn't buffer. Over TCP, the same walk causes a 2-3 second rebuffer every time the IP changes. It's the kind of improvement you don't notice until someone points out that you used to notice the stutter.
Google Built It, Then Standardised It
QUIC didn't come from a standards committee. Google built it, started Chrome experiments in late 2012/early 2013, rolled it out to users over the next couple of years, and ran it against their own servers for years before proposing it to the IETF. By the time RFC 9000 was published in 2021, more than half of Google's traffic was already running over QUIC. YouTube, Search, Gmail, Maps -- all QUIC. A land grab I can get behind.
The IETF version diverged from Google's original in meaningful ways (different packet format, different header protection), but the core idea survived: independent streams over an encrypted UDP transport.
The Performance Reality
The benchmarks tell a nuanced story.
HTTP/2 versus HTTP/1.1 on a clean, wired connection: modest improvement. The multiplexing helps, the header compression helps, but the RTT savings from a single connection are small when the latency is already 5ms. On a high-latency connection -- satellite, intercontinental, mobile -- the improvement is dramatic. One handshake instead of six. One congestion window that warms up once instead of six that warm up independently.
HTTP/3 versus HTTP/2 on a clean network: almost identical. If you're not losing packets, independent streams don't matter. QUIC's faster handshake saves one RTT on the initial connection -- noticeable but not transformative.
Where HTTP/3 wins is lossy networks. Mobile. WiFi in a conference center with 500 developers all running npm install. A train. Anywhere packet loss is above 1%. That's where TCP's head-of-line blocking makes HTTP/2 stutter, and QUIC's independent streams keep delivering.
The 0-RTT resumption matters most for the mobile web -- short-lived sessions where the handshake cost is a significant fraction of the total page load time. If your users are on a 200ms mobile connection and loading your page cold, those two saved round trips are 400ms. That's the difference between feeling fast and feeling sluggish.
Why you still need HTTP/1.1 support: corporate proxies that terminate and re-establish connections, running HTTPS inspection that doesn't understand HTTP/2 framing. Legacy load balancers. Some CDN configurations. QUIC gets blocked entirely by enterprise firewalls that don't recognize it -- browsers fall back to HTTP/2 over TCP silently.
Seeing It in the Wild
Chrome DevTools
Open DevTools. Click the Network tab. Right-click any column header and enable "Protocol." You'll see h2 for HTTP/2, h3 for HTTP/3, and http/1.1 for the holdouts. Load google.com and watch: most requests will show h3. Load a smaller site and you'll probably see h2. Load a government website from 2014 and you might see http/1.1.
curl
$ curl -v https://google.com 2>&1 | grep -i "ALPN\|using HTTP"
* ALPN: curl offers h2,http/1.1
* ALPN: server accepted h2
* using HTTP/2
That's TLS ALPN negotiation in action — covered in post 20 (TLS). curl offers h2 and http/1.1, the server picks h2, and the connection is HTTP/2 from the first byte of application data.
For HTTP/3, your curl needs to be built with QUIC support (--with-nghttp3). Most system curls aren't:
$ curl -v --http3 https://cloudflare.com
curl: option --http3: the installed libcurl version does not support this
If you see that, it's not a server problem — your curl binary wasn't compiled with nghttp3. But someone else already built one:
$ docker run --rm alpine/curl-http3 curl -v --http3 https://google.com 2>&1 | grep -i "http/"
* using HTTP/3
> GET / HTTP/3
< HTTP/3 301
HTTP/3 over QUIC over UDP. No TCP handshake, no separate TLS negotiation. One round trip and you're in.
In Chrome, QUIC is enabled by default (chrome://flags/#enable-quic if you want to verify or toggle it). To see it working: DevTools → Network tab → right-click any column header → enable "Protocol." Load google.com and you'll see h3 next to most requests. chrome://net-internals/#quic shows active QUIC sessions if you want the raw connection details.
Your site might serve HTTP/3 to Chrome but HTTP/2 to curl. Here's why: HTTP/3 discovery uses the Alt-Svc header. The server sends alt-svc: h3=":443" in an HTTP/2 response, telling the client "I support HTTP/3 on this port." The browser remembers this and uses QUIC for subsequent connections. Curl doesn't cache Alt-Svc headers between invocations -- every curl command starts fresh, connects over TCP, and gets HTTP/2.
Chrome also sends a DNS query for HTTPS records (post 07) which can advertise HTTP/3 support before any TCP connection is established.
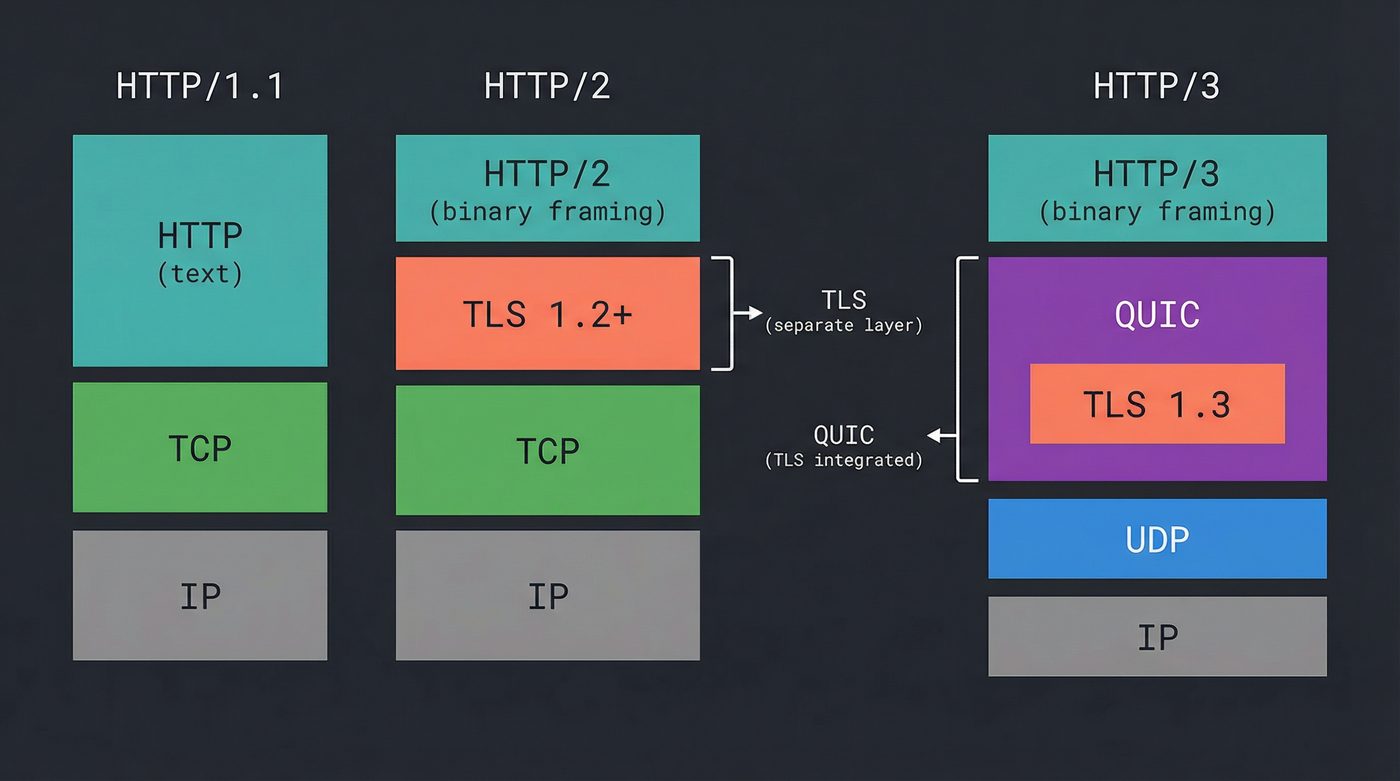
The Whole Stack, Three Ways
Here's what's happening between your browser and the server in each version, from the network up:
HTTP/1.1 (1999) HTTP/2 (2015) HTTP/3 (2022)
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ HTTP/1.1 │ text │ HTTP/2 │ binary │ HTTP/3 │ binary
│ (plaintext) │ parsing │ (streams, │ framing │ (streams, │ framing
│ │ │ frames) │ │ frames) │
├──────────────┤ ├──────────────┤ ├──────────────┤
│ │ │ TLS 1.2+ │ separate │ │
│ (no TLS │ │ (layered) │ handshake │ QUIC │ TLS 1.3
│ required) │ │ │ │ (baked in) │ built-in
├──────────────┤ ├──────────────┤ ├──────────────┤
│ TCP │ ordered │ TCP │ ordered │ UDP │ unordered
│ │ byte stream │ │ byte stream│ │ datagrams
├──────────────┤ ├──────────────┤ ├──────────────┤
│ IP │ │ IP │ │ IP │
└──────────────┘ └──────────────┘ └──────────────┘
HOL blocking: HOL blocking: HOL blocking:
Application layer Transport layer None (per-stream)
Each version is an answer to the previous version's deepest problem. HTTP/1.1's application-layer head-of-line blocking begat HTTP/2's multiplexing. HTTP/2's transport-layer head-of-line blocking begat QUIC. And Google looked upon QUIC, and saw that it was good. And there was much rejoicing among the CDN operators (yay). QUIC's independent streams finally killed head-of-line blocking entirely -- by leaving behind the transport protocol that enforced it for forty years.
TCP served the web for twenty-five years. It's still underneath HTTP/2, and it's still the fallback when QUIC can't get through a firewall. TCP isn't dead (post 08). But for the first time, the web has a transport layer that was designed for the web -- not inherited from an era when loading a page meant one HTML file and two images.
The next time your phone switches from WiFi to cellular and the page doesn't stutter, that's QUIC. The next time you load a site on airplane WiFi and it doesn't feel like 2008, that's independent streams. The protocol keeps reinventing itself because the network keeps getting worse in new and creative ways, and each time, someone looks at the layer below and says "we can fix it there."
Further Reading
- What "Connected" Means in TCP -- TCP's connection model and why its ordered byte stream creates head-of-line blocking for HTTP/2.
- The Handshake You Never See -- TLS 1.3 is baked into QUIC. Understanding the standalone handshake makes the integration clearer.
- Your DNS is Lying to You -- DNS HTTPS records advertise HTTP/3 support before any connection is established.
- RFC 9114: HTTP/3 -- The HTTP/3 specification. Shorter than you'd expect.
- RFC 9000: QUIC: A UDP-Based Multiplexed and Secure Transport -- The QUIC transport protocol. This is the interesting one.
- RFC 7540: Hypertext Transfer Protocol Version 2 (HTTP/2) -- The HTTP/2 spec. Superseded by RFC 9113 but still widely referenced.
- Cloudflare: The Road to QUIC -- Practical deployment perspective from a CDN that serves a significant chunk of the internet over QUIC.
- HTTP/3 explained -- Daniel Stenberg (curl author) explains HTTP/3 and QUIC. Free, thorough, readable.
I'm writing a book about what makes developers irreplaceable in the age of AI. Join the early access list →
Naz Quadri once domain-sharded a site across four subdomains before realising the CDN was already doing it and he'd quadrupled his DNS lookups for nothing. He blogs at nazquadri.dev. Rabbit holes all the way down 🐇🕳️.